API Integration Challenges and How to Handle 4 of Them

These days, organizations are increasingly reliant on 3rd-party APIs. Perhaps the market is too hot to wait to release a new feature. Maybe the organization simply does not have sufficient expertise or capabilities to build the functionalities in-house. Sometimes the organization does not want to lose the core business focus, or it can’t afford new specialists and is going through a recruiting freeze.
Whatever the reason, integrating APIs into the organization’s existing platform can bring new obstacles. Let’s review the top 4 challenges and find ways to overcome them.
Challenge 1:
Event Transmission/Capture Failure
Consider a scenario where the client platform is sending an appropriately formatted payload to the 3rd-party API. The API will use this data to reach a certain (success/failure/perpetually hung!) state and return the relevant information to the client. The client captures that information and processes it further down, and leave the user a custom reply.
What if this API/Client bridge breaks? It can go in multiple ways: the client may fail to send the properly formatted request, API may fail to send the data to the client, or the client may fail to receive the data from the API. This can lead the user to a wobbly state and eventually stress her so much that she will go on calling the customer service several times at midnight (true story!) or simply leave the site to move to a competitor and never ever return. In any case, this is no doubt bad business.
Here are two ways to handle this scenario:
- Consumer/API Provider Acknowledgments: Institute an acknowledgment-based API.
- The client sends data to the 3rd-party API
- API acknowledges that it indeed received the client data
- API processes the client data and sends back a response
- The client captures the response, calls 3rd-party’s acknowledgment API and confirms that it indeed got the expected
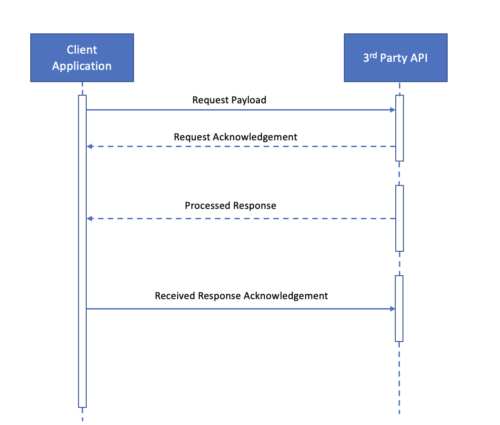
- Acknowledgment Failure: It is possible that acknowledgment fails at step (b) or (c). If this happens at step (b), the client can institute a retry mechanism where it tries to send the payload again and again, up to a pre-determined max limit or until a max time limit. After that, the client can show the user an error message and request her to take an alternative course of action. The development team can handle the failure to acknowledge at step (c) in several ways:
- The client can track the timestamp of sending the data to the API (probably through a callback from the receiver API, e.g., an operation initiation API call) and waits until a certain threshold (usually, this is a learned measurement) passes. If it fails to capture the response, it’s a red flag and automatically triggers the acknowledgment API with a failed status.
- The API can also track the call initiation timestamp and after a threshold limit, sends the client a failure message with possible details. The client can then try to re-send the data to the API for another (or a few more) time(s); otherwise, the API can reprocess the payload, possibly increasing the agreed time limit for acknowledgment.
The above failures may not be one-off cases and there is a good chance that these are quite common occurrences at the beginning phase of the project development when the requirements are fuzzy and the developers/stakeholders in the consumer and API teams have not interacted much. It is often good to re-process the failed requests in a separate batch job. One little setback in this approach is if the batch job sends users some confirmations, they will be delayed – depending on when the batch is fired, batch size, or the frequency of running. The user experience will not be optimal, but at least the system’s correctness gets preserved, and the users get some sort of feedback from the client.
Challenge 2:
API Availability Loss
It is necessary that the integrated 3rd-party solution is stable. If it crashes too often or behaves too erratically, the client can lose business. There are several metrics such as uptime, errors/minute, latency, etc. One way to minimize the business impact, especially during the beginning phases, is to make the solution client flag dependent. The client can configure this on/off flag in the database or in the front end. QA can test the application in a pre-prod environment with the flag turned on; prod may continue to run with the flag off. Once the internal users are happy, client developers can turn on the flag and make the feature available in prod.
This strategy is useful even after the initial release. If the API provider accidentally releases an incompatible update or a bug, the client can turn the flag off. The feature might be temporarily unavailable, but the client can avoid user wrath in the courthouse. Turning on and off the flag should be as much release independent as possible; so it’s probably a better approach to do this in the backend.
Challenge 3:
Duplicate API Responses
Sometimes, an API can return the same messages multiple times, within a fraction of a second. The client application may listen to them and send the information successively down the line. Thus, backend may see a lot of duplicate records, probably differing only in the create/update times making reporting difficult.
The client can prevent this from happening on two fronts:
- In the backend, before inserting/updating any crucial data, the application can verify whether the entry already exists in the database. Developers can use a temporary index table here that would be cleaned up periodically after the data are successfully processed. If an entry is not there, only then the application will proceed to do the rest of the backend operation; otherwise, it would do nothing (probably adding a log on the event details will help fetch more information).
- The client, on the frontend, can successively remove and add events based on whether it has already processed the response.
Challenge 4:
Security Threats
It goes without saying, ensuring that hackers cannot manipulate the API is utterly important. Imagine if a hacker gets access to the payload and header structure, she can arbitrarily modify the numbers and cripple the end-to-end business flow (e.g., inventory loss, refund hassles, revenue disruption, etc.).
At a bare minimum, developers can assign a secret custom header to the API calls. The caller should know this header and use it to get the response back from the API. Most often, if implemented right, basic auth (a combination of username and password) works fine to protect the API. For a more secure setup, API could be protected through an OAuth2 based system – an authentication API that generates a valid time-sensitive (this is important to prevent from brute-force re-executions) token/session key and the actual API whose execution needs that key as a passed down parameter.
Final Words
In conclusion, 3rd-party APIs can help the client organizations add/improve more features quickly but integrating them into its platform is hardly “seamless”. The above issues are just the tip of the iceberg and the developers often find new challenges in the process. That is when a careful API design may come in handy – it should gauge the feedback of both the consumer and API provider to examine what is currently possible given limited time and resources.