Automate Azure Databricks Job Execution with Python Functions

Thanks to a recent Azure Databricks project, I’ve gained insight into some of the configuration components, issues and key elements of the platform. Let’s take a look at this project to give you some insight into successfully developing, testing, and deploying artifacts and executing models.
One note: This post is not meant to be an exhaustive look into all the issues and required Databricks elements. Instead, let’s focus on a custom Python script I developed to automate model/Job execution using the Databricks Jobs REST APIs. The script will be deployed to extend the functionality of the current CICD pipeline.
Background of the Databricks project
I’ve been involved in an Azure Databricks project for a few months now. The objective was to investigate the Databricks platform and determine best practice configuration and recommendations that will enable the client to successfully migrate and execute their machine learning models.
We started with a proof of concept phase to demonstrate some of the features and capabilities of the Databricks platform, then moved on to a Pilot phase.
The objective of the Pilot phase was to migrate the execution of machine learning models and their datasets from the Azure HDInsight and Apache Hive platform to Azure Databricks and Spark SQL. A few cons with the HDInsight platform had become obvious, some of which included:
a) Huge administrative overhead and time to configure and provision HDInsight clusters which can run into hours.
b) Limitations in managing the state of HDInsight Clusters, which can’t really be shut down without deleting the cluster. The autoscaling and auto-termination features in Azure Databricks play a big role in cost control and overall Cluster management.
c) Model execution times are considerably longer on Azure HDInsight than on Azure Databricks.
Key Databricks elements, tools and issues
Some of the issues faced are related to:
- Data Quality: We had to develop Spark code (using the PySpark API) to implement Data clean up, handle trailing and leading spaces and replace null string values. These were mostly due to the Data type differences between HDInsight Hive and Spark on Databricks, e.g char types on Hive and String types on Spark.
- End-to-end CICD Tooling: We configured Azure Pipeline and Repos to cover specific areas of the CICD pipeline to the Databricks platform, but this was not sufficient for automating Model execution on Databricks without writing custom python code to implement this functionality.
- Development: Implementing RStudio Server deployment on a Databricks Cluster to help with the development and debugging of models.
- Azure Data Factory: We explored version 2, but at the time of initial testing, version control integration was not supported. At the time of this writing though, it is supported. While the configuration works and I confirmed connectivity to my Github repository, it appears the current integration allows for an ADF Pipeline template to be pushed to the defined repository root folder. I have not been able to import existing notebook code from my repo, to be used as a Notebook activity. Maybe this use case is currently not supported/required or I’m yet to figure it out. Will continue to review.
- Azure Databricks VNET Peering: Connecting the Azure Databricks workspace with existing production VNET was not possible at the start of this engagement. VNET peering is now currently supported.
Other Databricks elements and tools include:
- Databricks Hive Metastore: Databricks’ central hive metastore that allows for the persistence of table data and metadata.
- Databricks File System (DBFS): The DBFS is a distributed file system that is a layer over Azure Blob Storage. Files in DBFS persist to Azure Storage Account or AWS S3 bucket, so there’s no data loss even after a Cluster termination.
- Cluster Init Scripts: These are critical for the successful installation of the custom R package dependencies on Databricks Clusters, keeping in mind that R does not appear to have as much feature and functionality support on Databricks as Python and Scala. At least at this time.
- Databricks CLI: This is a python-based command-line, tool built on top of the Databricks REST API.
- Databricks Notebooks: These enable collaboration, In-line multi-language support via magic commands, Data exploration during testing which in turn reduces code rewrites. I’m able to write PySpark and Spark SQL code and test them out before formally integrating them in Spark jobs.
- Databricks-Connect: This is a python-based Spark client library that let us connect our IDE (Visual Studio Code, IntelliJ, Eclipse, PyCharm, e.t.c), to Databricks clusters and run Spark code. With this tool, I can write jobs using Spark native APIs like dbutils and have them execute remotely on a Databricks cluster instead of in the local Spark session.
- DevOps: The steps involved in the integration of Databricks Notebooks and RStudio on Databricks with version control are pretty much straightforward. A number of version control solutions are currently supported: Bitbucket, Github and Azure DevOps. This brings me to the focus of this post. At the time of this writing, there is currently no CICD solution (that we know of), capable of implementing an end-to-end CICD pipeline for Databricks. We used the Azure DevOps Pipeline and Repos services to cover specific phases of the CICD pipeline, but I had to develop a custom Python script to deploy existing artifacts to the Databricks File System (DBFS) and automatically execute a job on a Databricks jobs cluster on a predefined schedule or run on submit.
- MLFlow on Databricks: This new tool is described as an open source platform for managing the end-to-end machine learning lifecycle. It has three primary components: Tracking, Models, and Projects. It’s still in beta and I haven’t reviewed it in detail. I plan to do so in the coming weeks.
Solution using Python libraries
Databricks Jobs are the mechanism to submit Spark application code for execution on the Databricks Cluster. In this Custom script, I use standard and third-party python libraries to create https request headers and message data and configure the Databricks token on the build server. It also checks for the existence of specific DBFS-based folders/files and Databricks workspace directories and notebooks. It will delete them if necessary while creating required folders, copy existing artifacts and cluster init scripts for custom package installation on the Databricks Cluster, and create and submit a Databricks Job using the REST APIs and execute/run the job.
Let’s look at specific parts of the Python script.
Configure header and message data:
import sys
import base64
import subprocess
import json
import requests
import argparse
import logging
import yaml
from pprint import pprint
JOB_SRC_PATH = “c:/bitbucket/databricks_repo/Jobs/job_demo.ipynb”
JOB_DEST_PATH = “/notebooks/jobs_demo”
INIT_SCRIPT_SRC_PATH = “c:/bitbucket/databricks_repo/Workspace-DB50/cluster-init1a.sh”
INIT_SCRIPT_DEST_PATH = “dbfs:/databricks/rstudio/”
RSTUDIO_FS_PATH = “dbfs:/databricks/rstudio”
WORKSPACE_PATH = “/notebooks”
JOB_JSON_PATH = “c:/BitBucket/databricks_repo/Jobs/databricks_new_cluster_job.json”
with open(“c:\\bitbucket\\databricks_repo\\jobs\\databricks_vars_file.yaml”) as config_yml_file:
databricks_vars = yaml.safe_load(config_yml_file)
JOBSENDPOINT = databricks_vars[“databricks-config”][“host”]
DATABRICKSTOKEN = databricks_vars[“databricks-config”][“token”]
def create_api_post_args(token, job_jsonpath):
WORKSPACETOKEN = token.encode(“ASCII”)
headers = {‘Authorization’: b”Basic ” +
base64.standard_b64encode(b”token:” + WORKSPACETOKEN)}
with open(job_jsonpath) as json_read:
json_data = json.load(json_read)
data = json_data
return headers, data
Configure Databricks Token on Build server:
#Configure token function
def config_databricks_token(token):
"""Configure
databricks token"""
try:
databricks_config_path = "c:/Users/juser/.databrickscfg"
with open(databricks_config_path, "w") as f:
clear_file = f.truncate()
databricks_config = ["[DEFAULT]\n","host = https://eastus.azuredatabricks.net\n","token = {}\n".format(token),"\n"]
f.writelines(databricks_config)
except Exception as err:
logging.debug("Exception occured:", exc_info = True)
Create and run the job using the Python subprocess module that calls the databricks-cli external tool:
def create_job(job_endpoint, header_config, data):
"""Create
Azure Databricks Spark Notebook Task Job"""
try:
response = requests.post(
job_endpoint,
headers=header_config,
json=data
)
return response
except Exception as err:
logging.debug("Exception occured with create_job:", exc_info = True)
def run_job(job_id):
“””Use the passed job id to run a job.
To be used with the create jobs api only, not the run-submit jobs api”””
try:
subprocess.call(“databricks jobs run-now –job-id {}”.format(job_id))
except subprocess.CalledProcessError as err:
logging.debug(“Exception occured with create_job:”, exc_info = True)
The actual Job task is executed as a notebook task as defined in the Job json file. The notebook task which contains sample PySpark ETL code, was used in order to demonstrate the preferred method for running an R based model at this time. The following Job tasks are currently supported in Databricks: notebook_task, spark_jar_task, spark_python_task, spark_submit_task. None of the defined tasks can be used to run R based code/model except the notebook_task. The spark_submit_task accepts --jars and --py-files to add Java and Python libraries, but not R packages which are packaged as “tar.gzip” files.
In the custom functions, I used the subprocess python module in combination with the databricks-cli tool to copy the artifacts to the remote Databricks workspace. The Create Jobs API was used instead of the Runs-Submit API because the former makes the Spark UI available after job completion, to view and investigate the job stages in the event of a failure. In addition, email notification is enabled using the Create Jobs REST API, which is not available with the Runs-Submit Jobs API. A screen shot of the Spark UI is attached:
Job Status:
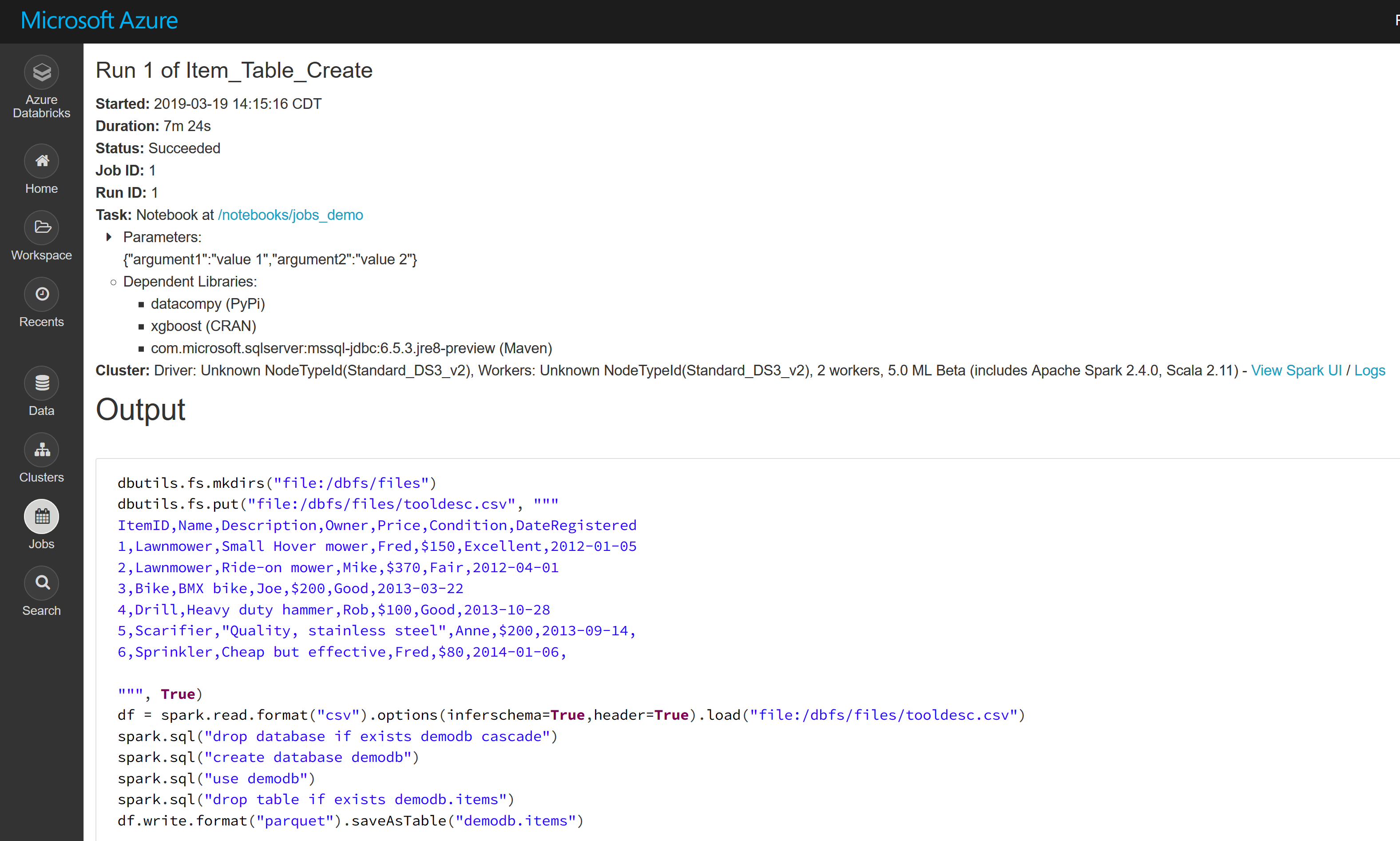
Spark Job View:
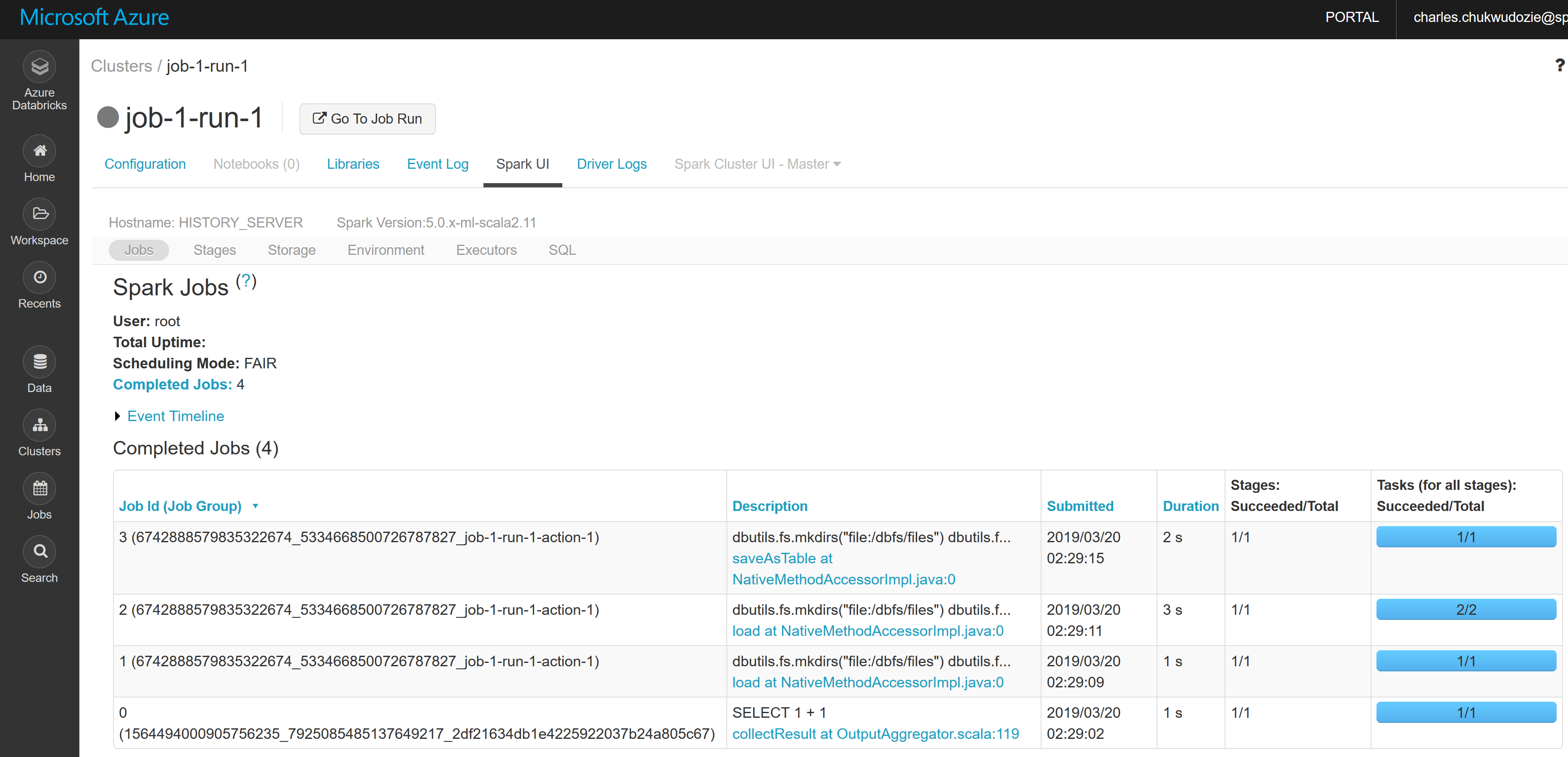
Spark Job Stages:

A snippet of the JSON request code for the job showing the notebook_task section is as follows:
{...
"timeout_seconds": 3600,
"max_retries": 1,
"notebook_task": {
"_comment": "path param||notebook_path||notebooks/python_notebook",
"notebook_path": "/notebooks/jobs_demo",
"base_parameters": {
"argument1": "value 1",
"argument2": "value 2"
}
}
}
I developed this Python script to extend the existing features of a CICD pipeline for Azure Databricks. I’m continuously updating it to take advantage of new features being introduced into the Azure Databricks ecosystem and possibly integrate it with tools still in development. That could potentially improve the end-to-end Azure Databricks/Machine learning workflow.
The complete code can be found here.


