Azure Integration Part III: Azure Storage Offerings

(Note: this is a multi-part series. You can start at the beginning or go back to Part 2.)
When developing your integration solutions in Azure, there is no doubt that there will be discussions on which storage offerings you will want to use. Depending on the requirements, there will be an offering in Microsoft Azure that will be available.
In Part 3, we will focus on some of these different storage options that are available for any solution integrating with Microsoft Azure. We will discuss Azure Storage Tables, Azure SQL Database, SQL Server on VM, Azure SQL Data Warehouse, Data Lake Store and DocumentDB.
Azure Storage Table
When looking for a NoSQL schema-less storage solution for structured data, one might want to look at Microsoft’s Azure Table Storage offering. This Azure service has the advantages that come with Azure Storages, in that it is durable, highly available and scalable for any solution.
Azure Storage Tables are not like traditional relational databases. It does not have your typical defined set of pre-defined columns, with one or more keys, that can be used to identify relationships with other tables. Instead, it uses a key/attribute store that is used to store structured NoSQL data with a schemaless design. This design allows your application to adapt the changes in your data. Essentially, when you create an Azure Storage account,
- You can have one to many Azure storage tables.
- For each Azure storage table, you can have one to many partitions.
- Within each partition, you have one to many rows.
- Each row contains properties for a partition key, a row key and a timestamp. In addition, you can have up to 252 other properties with name value pairs (255 total properties).
- The partition key and row key must be unique.
Table storage offers durability by storing your data multiple times. Below are the different options:
- Locally Redundant Storage (LRS): Makes multiple synchronous copies of your data within a single datacenter. It will protect your data from normal hardware failures, but not from the failure of a single data center. For maximum durability, it is recommended that you use geo-redundant storage.
- Geographically Redundant Storage (GRS): Like LRS in that it will make multiple synchronous copies of your data within a single datacenter, plus multiple asynchronous copies to a second datacenter hundreds of miles away that is nearest the primary datacenter. If the primary datacenter goes down, it will failover to the secondary datacenter. This ensures your data is durable in 2 separate datacenters which are in separate regions.
- Read-Access Geographically Redundant Storage (RA-GRS): This is identical to GRS, but it will give your read access to your data from the secondary datacenter. Read-access geo-redundant storage is the default option for your storage account by default when you create it.
For most cases, Azure Table should be more cost effective than using traditional relational database, such as, Azure SQL Server. Looking at the table below for LRS, let’s say we have 10 million transactions and have 500GB of data. That would cost about $2.23 for the transactions (10,000,000 divided by 100,000 times .0036 = 0.36) and $60 for storage (500 times .12), totaling $35.36 with LRS or 60.36 with RA-GRS.
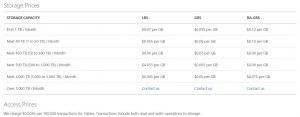
Typically, you will want to consider using Azure storage when you need cheaper, cost effective storage and if you will have high volume.
Azure SQL Database
When it comes to a relational database management system, Microsoft SQL Server is one of the most widely used today. In Azure, they offer 2 options we will talk about.
Let’s first talk about their RDMS platform as a cloud service offering called Azure SQL Database. With this being a cloud service, you pay-as-you-go with options to scale up or out for increasing compute power with no interruption.
Also, because it is a Platform as a Service (PaaS), you can save on operational cost, because you can provision and manage databases without having to worry about having company resources to manage VMs, operating system or database software.
Another advantage that Azure SQL Database has, is that it supports existing SQL Server Tools, libraries and APIs which means that you can leverage existing SQL Server skillsets and knowledge without having to learn new skills.
With Azure SQL Database, it is dynamically scalable, meaning you can change the service tier based on current resource requirements on the fly and pay for resources only when you need them. This is done by changing one of the 3 service tiers, Basic, Standard and Premium and requires no downtime. Basic tier might be best used for small scale databases. Whereas, Premium would be best for very high volumes of transactions and have many concurrent users. Standard will fall somewhere in between. Look at the current differences in service tiers below.
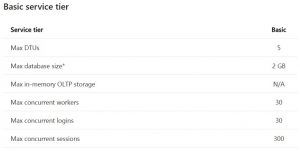
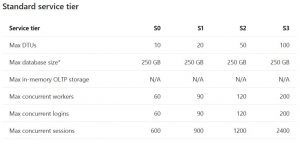
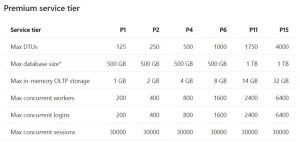
Another resourcing option you have with Azure SQL Database is what’s called elastic pools. Basically, you allocate performance resources to a pool rather than dialing up/down a single database demand for resources. You pay for the collective resources of the pool rather than a single database. You can add/remove databases to the pool and can control the min/max resources of each pool.
As you can see in the service tiers, they have what are called DTUs/eDTUs (Database Throughput Units/elastic Database Transaction Units). A DTU is blended measure of CPU, memory, and data I/O and transaction log I/O. You can think of this as compute power, where the higher the DTUs the more resources available for a database. You can use the Azure SQL Database DTU Calculator to determine the approximate DTUs you might need.
Some of the benefits of Azure SQL Database are:
- Threat detection and alerts: Has built-in behavioral analysis, real-time alerts, a configurable threat policy, an audit log, and intelligent ways to detect and fix unusual patterns.
- Automatic tuning: Will continuously learn application patterns, adaptively self-tuning its performance, and automatically refining.
- Insight Availability: Has telemetry for tracking each query and its duration, frequency, and resource utilization, which will optimally tune your databases exactly to your queries. Provides insights to help minimize time tuning queries and troubleshooting performance issues.
- Automatic Administration: Automatically provides back-ups, disaster recovery failover, infrastructure maintenance, security and software patches, and feature updates and 99.99% availability.
- Layers of Protection: Provides multiple layers of data protection by encrypting data while at rest, in motion or in use, authenticating only authorized users against the database or application, and limiting user access to the appropriate subset of the data.
You will want to use Azure SQL Database when you have structured data that needs to be relational, have indexes and constraints. Also, if you want to get up and running and need rapid development and want to take advantage of the benefits of having a PaaS based service, then look into using this cloud database service.
Also, as you can see, depending on your service tier, it does have data limits, but as stated above, you can transparently change this depending your resource requirements. Overall, it will probably be costlier than having Azure Table storage, but has a lot more functionality.
SQL Server on Azure VM
Now that we have talked about the cloud service option, let us move on to the more familiar second option which is SQL Server on an Azure VM. This is more of what companies have in their current on premise implementation for a relational database.
SQL Server on an Azure VM is not like Azure SQL Database and the difference is that it is an example of Infrastructure as a Service(IaaS), where you are installing and running SQL Server in a Windows Server Virtual Machine that is hosted in Azure. You have full administrative control of SQL Server and Windows, but Microsoft will own, host and manage the hardware or VM. You can either pay-as you-go for a SQL Server license already included in a SQL Server image or easily use an existing license. All version and edition of SQL Server is supported.
The availability SLA is about 99.95% on the VM only. For a high availability scenario, it is recommended that you will stand up 2 VMs instances and setup the HA options in SQL Server (i.e. AlwaysOn Availability Groups). This will provide 99.99% database availability.
SQL Server on Azure virtual machines are best for existing applications that need to be migrated to the cloud with not a lot changes. These can be situations where you want to stand up a SQL Server that is for non-production, possibly in a development or testing scenario where you do not want to buy on-premises hardware.
Azure SQL on VM can also be used to extend existing on-premises applications in a more hybrid type scenario. This is a good option when your company has existing resources available to maintain VMs to do patching, backups and setting up high availability.
Azure SQL Datawarehouse
Azure SQL Data Warehouse is a massively parallel processing (MPP), fully managed, distributed data warehouse cloud service offering from Microsoft. The architecture is based on SQL Server and the Analytics Platform System. And since it is a cloud service, you won’t have to worry about patching, upgrades, maintenance and backups.
Azure SQL Data Warehouse can scale to dynamically grow and shrink compute resources in minutes or even seconds. It does this by spreading the data across many shared-nothing storage and processing across multiple nodes. More importantly, Microsoft built Azure SQL Data Warehouse so that the compute and the storage are independent of each other, and thus you can also grow and shrink storage separately. You only pay for the performance and storage only when you need it.
One of the nice things that you can do with Azure SQL Data Warehouse is that you can stop the compute resources. This means that you can save money by stopping compute resources when you don’t need them and turn them back on when you do. For example, maybe you don’t have applications or processing in the late evening hours or maybe on the weekends and thus you can stop the compute resource so you are not charged for it during those times. The only thing, however is that you still have to pay for the storage regardless of whether you stop compute resources or not.
Azure SQL Data Warehouse basically consists of a control node, many compute nodes, and storage. The way it works is this:
- Up front there is a control node.
- Control node receives the requests.
- Control node then optimizes it by transforming your T-SQL query into separate queries.
- Then distributes it on to separate compute nodes to run in parallel.
- If you are loading data, the compute nodes will handle the processing to add it to storage.
- If you are querying data, the compute nodes will get the results and send the results back to the control node.
- The control node will aggregate these results and send back a final result.
On the backend, the data that is written and read, are stored in Azure Storage Blobs. This allows it to scale storage and has the benefits you get with Azure storage. There is also service called the Data Movement Service (DMS). It is responsible for facilitating the data movement between the control and compute nodes and between the compute nodes themselves.
Similar to Azure SQL Database, the compute resources are based on Data Warehouse Units (DWU). It works the same in that the more DWUs you assign, the more resources are allocated for your data warehouse, which includes CPU, memory and storage I/O. This is how you can independently and easily scale up or down the compute resources you need, when you need it, based on your DWUs. Below is a sample pricing for Central US by hour
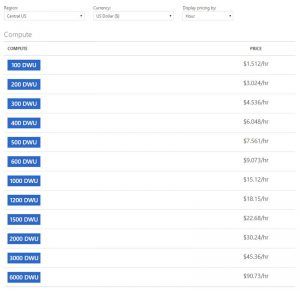
You can check you pricing on the Microsoft Azure SQL Data Warehouse Pricing page.
The other great thing with Azure SQL Data Warehouse is that it will work with existing data tools. This includes Power BI for data visualization, Azure Machine Learning for advanced analytics, Azure Data Factory for data orchestration and Azure HDInsight, our 100% Apache Hadoop managed big data service. It will also integrate with existing traditions SQL tools you might already be familiar with, such as SQL Server Analysis Services, Integration Services and Reporting Services.
And finally, Azure Data Warehouse has this great feature in that it can be used with PolyBase. With PolyBase, you have the ability to query non-relational data that is stored in Azure Storage Blobs and Hadoop using T-SQL. You can also import and export data from blob storage and Hadoop. You do not have to install additional software in Hadoop or Azure, as it all happens transparently. Obviously, this is a great benefit in that if you know already know T-SQL, you can access data in Hadoop or Azure blob storage using that existing skillset, is just wonderful!
Azure Data Lake Store
It is defined as a hyper-scale data store for big data analytic workloads, and when it comes to BigData, you have your various options out there, but with Azure Data Lake Store, Microsoft has built a wonderful product for storing BigData and optimized for analytics.
Azure Data Lake removes the restrictions found in some traditional analytic storages. It is built to store any type of data format that has no limits on account size or file size. With very high throughput for analytic performance and native integration with the Hadoop ecosystem. Azure Data Lake is a Hadoop File System compatible with HDFS that is integrated with Azure HDInsight and also integrates with Microsoft offerings such as Revolution-R Enterprise and industry standard distributions like Hortonworks and Cloudera.
With Azure Data Lake store, you get a storage that is very reliable and highly available. Microsoft will automatically replicate your data by creating 3 copies of it in the same regions. Another nice thing with Azure Data Lake store is that it’s made for unlimited storage. By this I mean that you are not limited to having X number of files, or possibly having issues with limits to storing large file sizes. For example, having a limit to be able to store a file that is larger than 100 gigabytes, ADL can store files that area gigabytes or petabytes in size.
What makes Azure Data Lake ideal for BigData and Analytics is that it is built to have very high throughput and it is optimized for parallelization. It will give you a lot more throughput levels for doing analytical computations than say Azure Storage Blobs, and because of this optimization it does cost a more. It is also has enhanced ways of reading data from the system through parallel computation over petabytes of data. Again, this is another reason why it is a great solution for Big Data workloads and for Analytics workloads requiring massive throughput as this is what it is optimized for.
Securing the data, it has POSIX-compliant ACLs on files and folders and integrates with Azure Active Directory, which means you can sync up your existing on premise AD security groups. Also, it is integrated with Azure Role-Based Access Control. With Access Control Auditing you will be able to know every operation on your files as everything is logged. You can do analytics and write U-SQL to parse these logs. You also don’t to worry about securing your data as your data is encrypted when it is stored and when it is in flight.
To move the data into your Azure Data Lake Store, you can use Azure Data Factory. As you can see from the diagram, Azure Data Factory is very flexible tool as it can read from the popular database sources into different Azure Sinks.

Ultimately, if you are building a solution that requires a BigData solution with Analytics then using Azure Data Lake Store is what you want to use. It is will meet your storage needs from because you can store anything in it’s native format without having to worry about size, and your data is secure and highly available.
Azure DocumentDB
Many are probably familiar with MongoDB, which is one of the more popular document based NoSQL database management systems. Microsoft has come out with their cloud version offering in Azure DocumentDb. With Azure DocumentDB, you have a fully managed, schema less, NoSQL database cloud service. The difference with this storage option as opposed to some of the others we have discussed, is that it stores the data as JSON documents in a database with collections. It uses JavaScript for the querying and it works with a JSON based data model.
It has very low latency as reading and writing takes milliseconds to execute. And because it uses SSD storage, Microsoft guarantees less than 10ms latencies on reads and less than 15 ms latencies on writes for at least 99 percent of requests.
It has limitless scale, as you can scale up or down as you see fits your needs. It has what is being considered planet scale capabilities, meaning depending on where your users are globally, you can replicate your data to a number of different regions around the world and scale by replicating your data to a region that is close to your users. This also helps with having low latency as say for example a user application in Europe won’t have to have fetch data stored in the US, whereas it can fetch the data in a datacenter closest to local European region.
DocumentDB lets you scale to billions of requests per day depending on your volume requirements of your application And like a few other of the storage options in this article, you have the option to change the storage and throughput parameters independently. With all these features and capabilities, Azure DocumentDB is well suited for applications such as IoT, web, mobile and gaming, ones that require enormous amounts of read/writes and need very low latency.
In conclusion, we have talked about a bunch of different storage offerings that Microsoft has in Azure. You have the options of less expensive storage that can still handle large volumes, to storage that can massively scale, to a storage solution that take any file format in any size. These different storage offerings will give any integration the right option and solution for your application. And with more applications integrating with the cloud, Microsoft Azure is giving you storage offerings that will meet the demands and requirements for today’s modern integration strategies.
In Part 4, we will go and talk about Azure Stream Analytics, Worker Roles and Web Roles.

