ChatGPT Fine Tuning: How to Build Improved Models

At this point, most people have seen ChatGPT’s impressive capabilities, but there’s a lot more to uncover, especially when considering ChatGPT fine tuning to enhance its performance. By using fine-tuned models on top of ChatGPT’s large language model, you can unlock further potential in specific tasks or domains.
In this blog post, we will explore ChatGPT fine tuning and what it entails.
WHAT IS CHATGPT FINE TUNING?
ChatGPT fine-tuning is the process of retraining an existing large language model (LLM), specifically the GPT models from OpenAI. These models, which include popular versions like GPT-3, GPT-3.5, and GPT-4, are the backbone of LLMs that serve several purposes.
The pre-trained model has already learned general patterns in language and can be fine-tuned to adapt to specific patterns for a new task or domain based upon your training data. Fine-tuning can help improve the performance of the model on the specific task, and it can also reduce the amount of data needed to train a model from scratch.
WHEN DOES FINE-TUNING CHATGPT MAKE SENSE?
A fine-tuned model typically makes sense in situations where you want to leverage the extensive capabilities of ChatGPT, but you need to supplement the model’s knowledge with other information.. It’s useful in situations where you want to leverage the extensive training of ChatGPT models, while expanding the level of knowledge on a specific topic. It can still have the same downsides of generic ChatGPT models, such as stating wrong information and needing to be trained as the information changes, so it is not a great choice for applications that require 100% factual certainty or with information that changes frequently. The next section describes in detail how to fine tune ChatGPT.
Steps to build a fine-tuned model in ChatGPT
To build a fine-tuned model in ChatGPT, follow these steps:
- Define the task and select the pre-trained model to use as a base. ChatGPT offers several pre-trained models with different token limits and capabilities. Choose the one that best.
- Prepare the data for training. Collect and clean the data, divide it into training and validation sets, then convert it into a format that can be fed into the model.
- Train the model on the fine-tuning task. Using OpenAI’s API, feed the training data into the existing model.
- Check the results and use the model. Measure the model’s performance on the specific task and adjust the model as necessary.
Now let’s dive into each of these steps with an example. Understanding how to fine-tune ChatGPT is key in this phase, ensuring that adjustments are accurately aligned with the desired outcomes. In our example, we’ll finetune ChatGPT on a topic it was not trained on - a fictitious character named Jonny Whizbang. This ensures that ChatGPT’s knowledge of the subject comes solely from our fine-tuning process and not its pre-existing knowledge.
Setting up your fine-tuned model
Before we begin, we will need an OpenAI API Key. Log in to your OpenAI account and create a secret key here. This key is essential for accessing the necessary resources to fine tune ChatGPT. Make sure to save the key somewhere safe and add it to your environment variables.

Additionally, make sure you have the OpenAI library available in your environment. We’re using Python so a simple pip install works here.

Define the task and select the pre-trained model
For our example, we’ll demystify how to fine tune ChatGPT to get a model that can answer questions about our fictional character. There are currently four base GPT-3 models (davinci, curie, babbage, and ada) available for fine tuning, each one with their respective strengths, weaknesses, and costs. For ours we will use curie. You can find more information here to decide what is best for your use case.
Prepare the data for training
As with all models, the data we put into it matters can make a huge difference. The data needs to be in a prompt-=completion format to train the model.

Our example is unique because the data about our fictional character must appear in the completion (answer) of questions we create and pose in the data.
{“prompt”: “When was Jonny Whizbang born?”, “completion”: “Jonny Whizbang was born on February 22, 1957.”}
For our example, I create a CSV with questions and answers you would expect to find in a basic biography such as birthdate, what the individual is known for, etc.
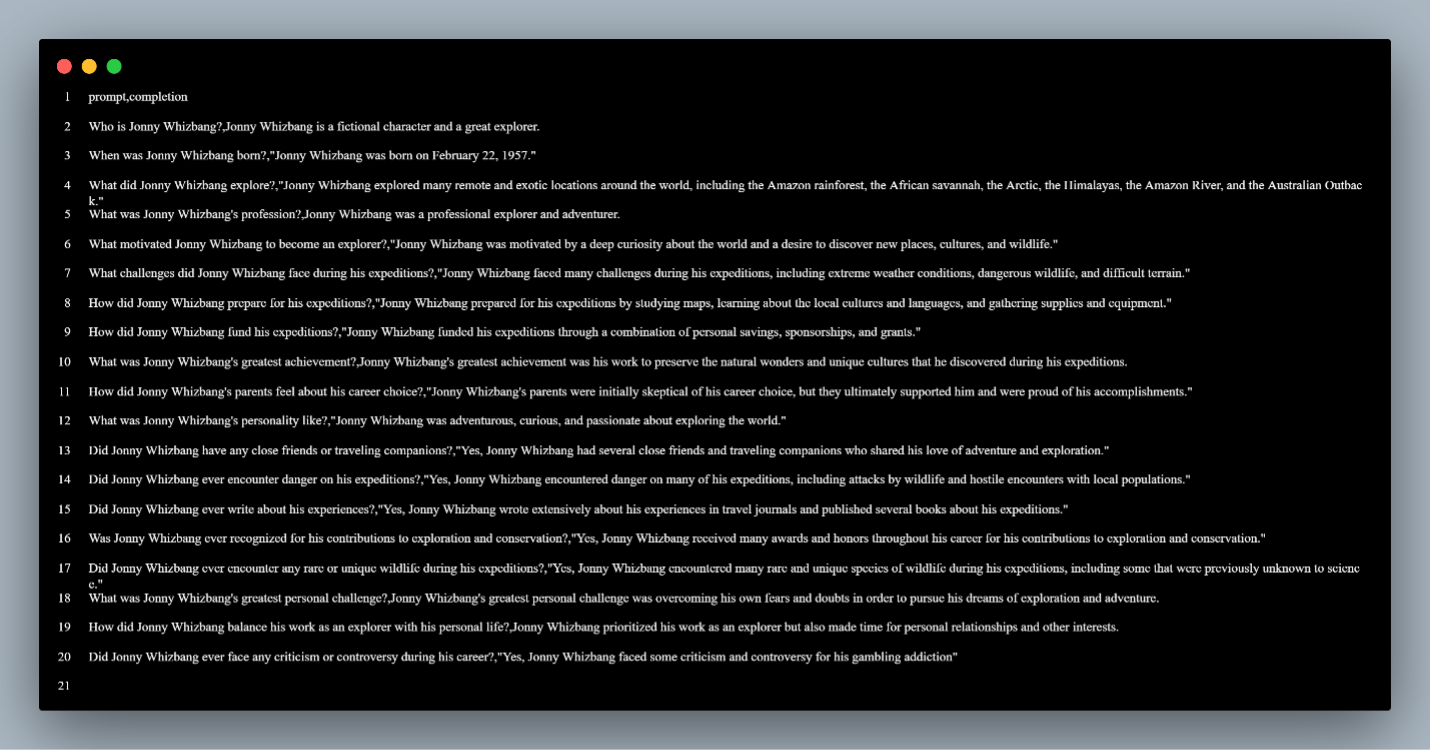
From there, we are ready to format the training data to fine tune ChatGPT.

Train the model on the fine-tuning task
Once the data is prepared, fine tuning ChatGPT is straightforward. One command with a few parameters does everything you need, although this can take some time to complete.

Once the tuning job starts, there are a few commands you can use to check the status.

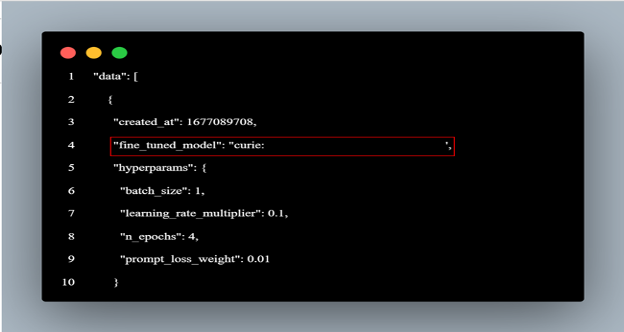
To use the model, you must have the fine-tuned model from the training job. The list command returns it below:
Check the results and use the model
Once you have completed the process of fine tuning ChatGPT, you can start asking it questions and seeing the responses. Let’s see if it knows the birthday of our fictional character.


Oops… It looks like that was incorrect. Let’s try something more specific.


Cool! It looks like it answered correctly.
Further Exploration
Practically speaking, it makes more sense to enhance this data a little bit more before starting to fine tune ChatGPT. We would like our data to be able to answer these questions even if they aren’t worded exactly like they are in the inputs. To do this, we could programmatically ask ChatGPT other ways to ask the questions in our data set and use the same response. This augmented data set will then be fed into the training data to make the model more robust.
Additionally, you could experiment with the different parameters involved in fine-tuning ChatGPT, such as temperature which controls how ‘creative’ the model is. Beyond that, there are other model types that can be fine tuned, including classification models. In an interesting application on OpenAI’s website, they use a classification model by fine-tuning ChatGPT to choose whether to respond to an input or determine if a question was = “off limits.” If the model decides to respond, then they leverage a question-and-answer model like we have here.
Fine-tuning is a powerful technique for adapting pre-trained models to specific tasks and domains, but still has the same chance of “hallucinating” and giving wrong answers. By mastering ChatGPT fine tuning as outlined in this blog post, you can create models that generate high-quality, task-specific text. Whether you are building a chatbot, writing a book, or analyzing text data, ChatGPT’s fine-tuning can help you achieve your goals with greater accuracy and efficiency.
