How ChatGPT Could Revolutionize UX Ways of Working

Artificial Intelligence. Amazing, fun, compelling and at the same time terrifying. Whether it’s deep fakes that hijack people’s images and voice patterns to create shockingly real replicas or AI art generators that disparage professionals in the art community over copyright issues, AI has ignited a firestorm of debate and demand for ethics, legality, and regulation. AI will give rise to executive level roles and specialized teams for digital ethics that are launched and integrated into the fabric of organizations that utilize machine learning and AI as a part of their products and services. At least, I truly hope so.
When you take a few steps back and a few deep breaths, interesting thought experiments around AI can abound, take shape, and not be too far off from practical and ethical application in the real world. This past October right before Open AI started blowing up, I was in a leadership team meeting when SPR’s CTO Matt Mead sparked my interest in ChatGPT as he talked about its ability to write poetry and song lyrics. Just a few days later in a UX team meeting, we were knee deep in topics of ethics, experimentation, and ways of working when one of our designers started talking about ChatGPT. “Enough already, I’m going to check it out,” I thought to myself. After reading a few primer articles about OpenAI’s program, the wheels were already well in motion for how a bot trained on rich data sets could benefit UX and potentially expand the business value of design within an organization by creating a single source of truth and awesomeness across IT, Marketing, and Product teams.
Join me on my initial exploration into ChatGPT and how it can revolutionize UX ways of working.
ChatGPT for Design
Waves of “how might we” (HMW) thought experiment questions began to swirl in my mind: How might ChatGPT be utilized for design experiments? How might we use it for ideation and collaboration workshops? Could it be used to accelerate or automate certain aspects of the design process? How might it be used to rapidly test design hypotheses and align on strategy and direction across multiple lines of business? Upon test driving the program, I decided to try a simple HMW statement to see how the bot handled it. I asked, “How might we design a solution for users that want to talk with their car when they are away from it?”

Gracefully ignoring my input error of including an extra “we” in my question, the bot replied with a coherent solution and potential functions of how a user might interact with their car and get key bits of information even when not physically with the vehicle. Pushing a little more, I asked a follow-up question for some additional ways we might design a solution and the bot responded with:
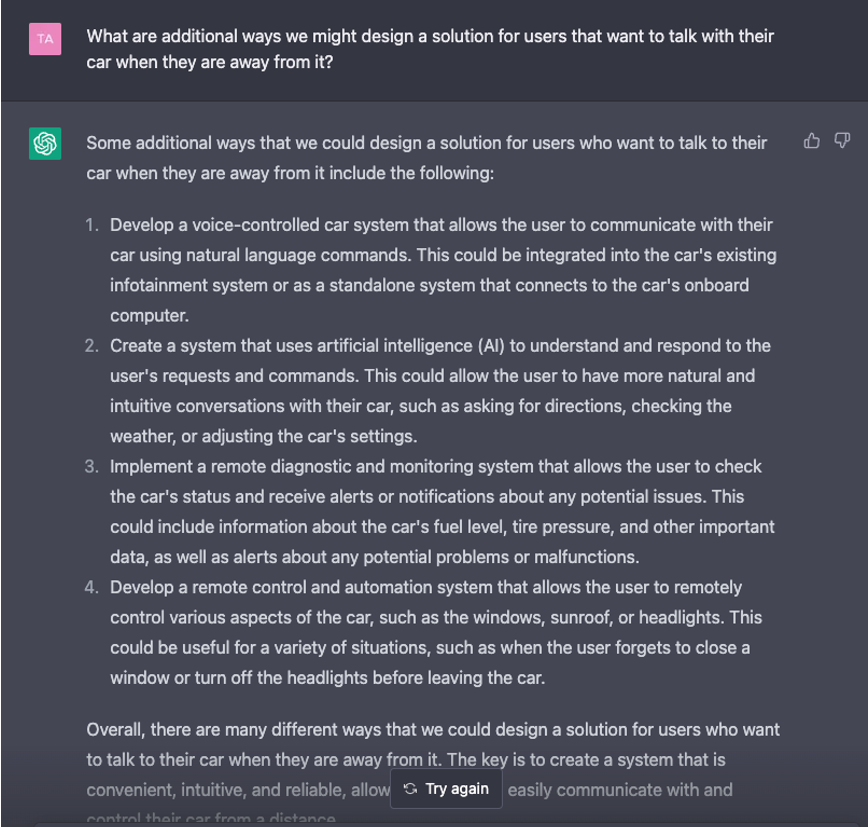
ChatGPT is impressive, fun and packed with potential, but I noticed how all of its answers were grounded in what’s possible from a technology perspective. This was great, however, I imagined how much more powerful and meaningful the bot’s responses would be if it had sets of quantitative and qualitative user data fed and trained into it, so it could respond as an empathy agent trained on an understanding of users and customers.
Imagine the Possibilities
The goal with any UX research is to not be wasteful. You achieve this by creating a quickly referenceable library of insights and empathy tools versus formal documentation and assets that once completed, often remain unused by an organization. Our UX team at SPR teaches and works with client product teams on how to organize their user research findings into a library from general to specific buckets like: Behavior Patterns, Shared Perceptions, Opportunity Space, Guiding Principles, and Empathy Maps. An insights library can also include cross-sections by user segment and customer type depending on your needs. It will often include collations of previously conducted research in addition to secondary research in the form of publicly published surveys, market data, and case studies that create a “bank” of research. The library becomes a periodically updated stockpile of user data available for quick reference when needing to guide design direction, answer questions related to product decisions and a meaningful resource for rapid product design.
Imagine if you would, all the above, a rich referenceable library of user research data organized and available at your fingertips in a system like ChatGPT. Because the bot is trained to know your users and customers, as well as trained on secondary sets of publicly available data, it would essentially become an empathy agent that UX and product teams could engage with quick queries, questions, and perhaps even thematic analysis. But let’s not stop there. What if over the course of time, the system could be trained on data from your marketing team, customer service, call center, and your actual digital product usage?
Hang on just a minute. The crazy design guy in the room is waving his hands around and getting passionate about the universe of possibilities. To ground this more in reality, I followed up with SPR’s Chief Architect, Greg Chambers, on the validity of the idea and just how feasible this might be to create. After walking Greg through the concept and types of data sets, he commented, “One of the biggest challenges with machine learning is getting clean data. If you could convert UX data into graph data and continue feeding in those data sets, then…. Well…. you’ve seen that somewhat controversial UX meme with the sidewalk and then the path that’s been cut through the grass by people walking? If you could get the machine to look at UX as graph data, it’d be like that, but in real time.”

This is why I love talking with technical architects. Imagine if you could take all of the flat data you get from a product analytics platform, combine it with your observational data, convert it to graph data and then train the machine, you’d have a very powerful empathy agent you could continue to grow and engage over time that would not only save time from having to dig through and mine tons of data, but you’d have a single source of insights at the fingertips of UX, product, and development teams as well.
ChatGPT in Use
While this is a fun thought experiment, I think the biggest and most immediate use cases the technology will tackle is going to be focused on data and analytics, business intelligence, and cyber security. But… as it becomes more established, understood, and proven, I think AI being integrated into the toolsets and UX ways of working, will become the norm. I look forward to seeing how it all plays out!