
So the question is, for the newly indoctrinated into the field of data science, is there too much focus on toolkits and languages and not enough on following the methodology and governance?
Don’t get me wrong, toolkits are invaluable in the development and deployment of data science projects. Toolkits are a means to an end. I have several that I use depending upon the nature of the problem. They are an efficient means to encapsulate and execute complex concepts as well as increase overall productivity. However, the data science process requires more attention, with a renewed focus on data exploration and the associated governance of data science projects.
Classic Data Science Process
As a quick reminder, the following depicts the classic data science process:
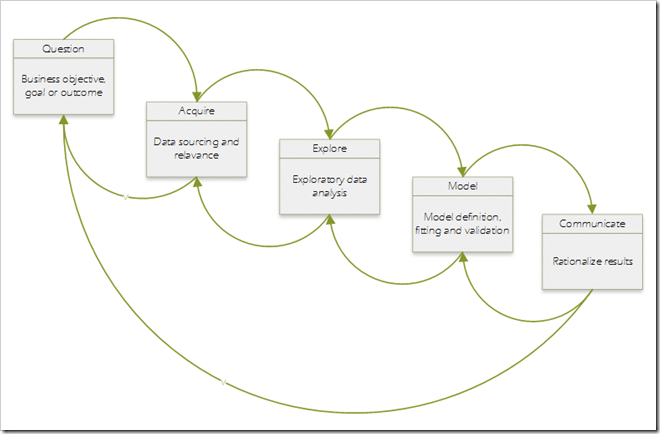
The well-defined iterative process of data science allows for a great deal of flexibility in its application. Data moves from one step to the other and, at any point in the process, a previous step may be executed as necessary.
The problems begin when you skip steps to accomplish a goal or objective quickly, which can lead to undesirable results. Sometimes the “Explore” step is skipped or is not given rigorous focus due to underestimating its value. This can be attributed to the hype associated with the flurry of new tools that have been introduced to the market that stress data acquisition and model building.
Also, data exploration can be a lengthy process where a lot of time is spent in the “Acquire” and “Explore” steps. Unfortunately, short-cutting the process can lead to:
- Inefficiencies – Looking for insights or relationships that do not exist or which could have been validated prior to building complex models
- Inaccurate results – Due to insufficient time being spent identifying obviously visible anomalies
- Loss of credibility – Lack of trust in the validity of developed solutions or outcomes
Data Exploration
Effectively leveraging data exploration can enhance the overall understanding of the characteristics of the data domain, thereby allowing for the creation of more accurate models. The following examples highlight some examples of effectively leveraging data exploration:
- Building a simple smoothing scatter plot to provide insights into the true nature of the relationship between variables.
- Employing basic data profiling to identify variable domain values, potential outliers, missing values and the need for normalization.
- Constructing a visual representation even before beginning a simple clustering analysis. This can be helpful if there is not a lot of data domain knowledge.
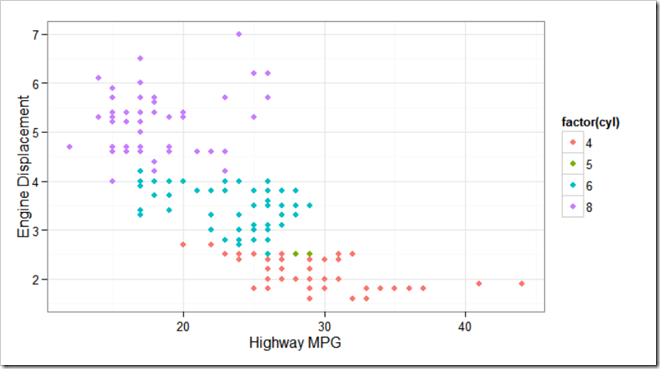
For example, in the following scatter plot, there are naturally forming clusters. This information can be used as input for building future models.
Guiding Principles
So what guiding principles from a data exploration perspective can be followed to maximize the data science process to achieve maximum effectiveness?
- Clearly Defined Objectives – Clearly communicate goals and objectives of the data science project to the team. This will focus the team on the expected outcomes. However, sometimes it’s the things not searched for that provide more interesting, unexpected insights and should be correlated with objectives and expected outcomes.
- Ignore the hype – Be wary when a toolkit/framework stresses modeling above all else without discussing how it implements the data science process.
- Discipline – Implement a governance process that captures and monitors output from each process step. Keeping in mind that the governance process must be flexible and adaptive such that it does not create excessive inertia.
- Education – Ensure all involved individuals have a high level understand of the data science process along with the value of and reason for each step (especially data exploration).
Remember, the data science process provides an approach that if followed will facilitate obtaining accurate results. Data exploration is a key step in that process that is invaluable in providing insights into the characteristics of the data domain. It is also guides the effective development, deployment and communication of model results.