Data truth – revisited

Background
Back in November 2009, during my then annual visit to the RSNA trade show event at McCormick Place in downtown Chicago, I came across a slogan on display in the Cerner Corporation exhibit which read “Single Source of TruthTM“. As a consultant, I was surprised that such a commonly used technology expression was granted a trademark.
And running across this slogan came shortly after my multiple stints at a healthcare insurance firm in which I had recalled the client CIO describing what he needed as “Single Source of Truth”. But in revisiting my discussions following the trade show, I was reminded that he had actually described his need as “Single Version of the Truth”, and used this expression interchangeably with “Single Source of Data”.
In 2010 and 2013, I wrote two variations of the same post to address the differences between “Single Source of Truth”, “Single Version of the Truth”, and “Single Source of Data”. After subsequently coming across the phrase “Source of Truth” within the context of a particular family of data related technologies, I have come to realize that these posts could use a revisit. This post provides a synthesis, starting with some earlier definitions:
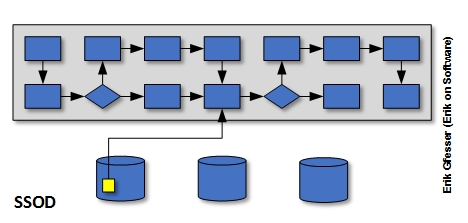
SSOD
Single Source of Data (SSOD) typically indicates that every data element is stored exactly once. In other words, every data element is stored in no more than a single row (record or tuple) of a single database table. Conceptually, this might look similar to the first diagram below. In this diagram, you will notice that although there are multiple databases across the enterprise, the truth that a particular process needs to access can only be found in one location.
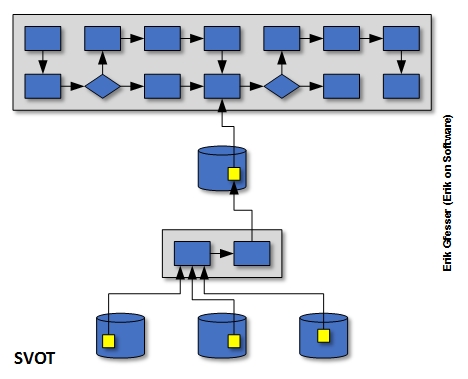
SVOT
Single Version of the Truth (SVOT) typically indicates that multiple versions of the truth can exist within an organization. One of the purposes behind a data warehousing initiative is to resolve these versions of the truth and to provide an “official” version of truth to the organization. One common reason multiple versions of the truth can exist is because such data can reside in organizational silos. Bill Inmon, the “father of data warehousing”, has eloquently described this concept in material he has written over the years.
Conceptually, this looks something like the second diagram below. You will notice that the truth an arbitrary process needs to access can only be found in one location, just as with SSOD, but with SVOT there exists additional logic between this truth and the source databases. This logic resolves any disputes these individual transactional databases might have with each other, and the resolution is stored in the data warehouse for the business process to utilize.
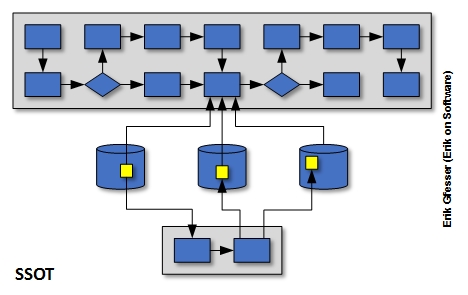
 SSOT
SSOT
Single Source of Truth (SSOT) is essentially synonymous with SSOD. However, once the term “truth” is referenced, it is usually the case that a data warehouse is involved, because while truth is assumed when a data element can only be found in one place, this assumption does not exist when a data element can be found in multiple places. The distinction that can be made between SSOT and SVOT is that the former can involve linkages to data elements by reference in other locales. When such data elements are updated, propagation is initiated across the enterprise so that duplicate data elements are always updated, resulting in the same “truth” regardless of which element is subsequently read by processes.
Now, as we move further away from the original concept presented, SSOD, there are more variations of methods to achieve truth, but conceptually SSOT looks akin to the third diagram below. As with SVOT, additional logic sits on top of the data in order to resolve differences, but multiple versions of truth do not exist in the original data. In this case, when the truth for a particular data element is updated, logic is initiated to propagate this data to other locales where this data element might also be stored, so that while there is a single source of truth, this truth might exist in multiple places where an arbitrary business process can access it.
(One additional note before moving on to the remainder of this post. As pointed out by an Oracle white paper that was published the year prior to my initial post, multiple versions of the truth might actually make sense for some data elements, because the more a term is connected to the core business, the more definitions of it might exist, with each valid definition being “One Context of the Truth”. This post is about tackling the meanings behind several similar-sounding phrases, not tackling the decisions around whether one or more definitions should exist.)
ShSOT ?
With brevity in mind, one important aspect that my earlier posts did not explain is how the concept of time can come into play. While SSOD indicates that every data element is stored exactly once in the enterprise, this scenario can often mean that each such data element is actually stored once for a given window of time, which means there are no conflicts with regard to version at a particular time. A bitemporal database table does not only store an effective time window for when data within a particular record is valid (i.e. business effective from- and to-dates), but a system effective time window for when the record itself is valid (i.e. system effective from- and to-dates).
So in other words, SSOD may contain multiple versions of a given data element, but only one version exists for a particular time, which means there are no conflicts that would require discussion of SVOT. Data streams handle the collection and delivery of data from continuous events, and one role of these mechanisms is to act as a buffer to hold event data as a protection against interrupted processing as data is ingested by consumers. Event data is not simply consumed and discarded like traditional queue mechanisms, but is instead persisted for a configured duration of time (or other metric). And since messages can reflect the changes of the same data elements within this time period, persistence means that the historical stream of messages can be replayed as if they were taking place for the first time.
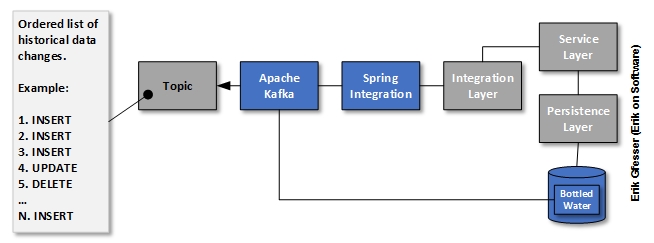
During a September 2016 talk I gave in Chicago, I walked through an illustration of how this works by presenting what change data capture (CDC) is all about, using traditional relational database products as a starting point. Every such database product stores an ordered list of historical database transactions in a log. This transaction log is what is used by the database to guarantee ACID properties in light of failure, reapplying changes as necessary if commits have not yet materialized. A similar concept can be demonstrated when using a database change management product such as Liquibase, which uses an ordered list of historical database schema changes stored in a database change log.
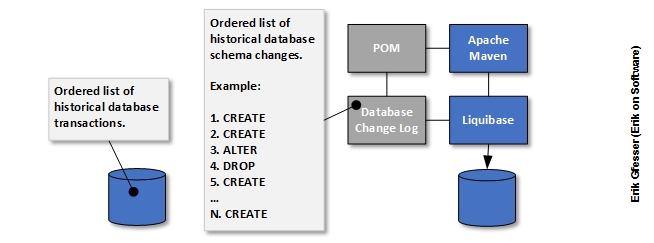
To round out my presentation of evolving a minimal viable product (MVP) over time, I showed how I extended an existing software application by adding the use of Apache Kafka (a stream processing platform) by way of Spring Integration and a PostgreSQL database extension called Bottled Water (not production ready at presentation time), which can be used to propagate an ordered list of historical data changes. These changes are stored in a Kafka topic as an ordered list conceptually similar to the first two lists discussed above, but it makes sense to mention that one of the differences here is that consumer specific offsets are stored to maintain what each consumer has already consumed (with the given that records can be replayed at a later point).
The relatively new data streaming community tends to make use of similar-sounding phrases when discussing this topic, most prevalently “Source of Truth” and “Shared Source of Truth”. For the purposes of the remainder of this discussion, let’s go with the latter (ShSOT). But is this label accurate? Is there any overlap here with “Single Source of Data”, “Single Version of the Truth” or “Single Source of Truth”?
One of the problems with using a single centralized database to hold transactional data for a large distributed system is that it becomes increasingly harder to maintain synchronized state for the current state of the business. With a streaming architecture, data records continuously flow between data sources and applications. The ShSOT is actually stored in shared in-motion event streams, sources of which some have come to call “infinite data sets”. These event streams are what store business history, with applications optionally storing local views of this data.
During a recent discussion, my audience reacted with a quizzical response when I commented that Kafka is essentially a database. While it may not have the same functionality as a traditional database, and some might prefer to call it a data store, queue, or “message transport”, there is no arguing that Kafka comprises an organized collection of data, and that traditional databases actually consist of event streams since they store ordered lists of historical database transactions. As Martin Kleppmann commented during his talk at Strange Loop 2014, the traditional database is essentially being turned inside out.
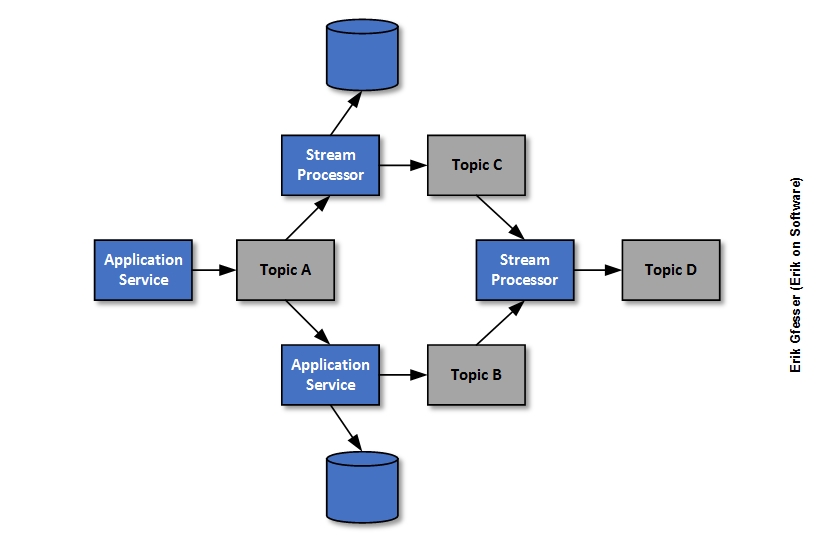
In the above diagram, topic A on the left is populated by an initial service, which is in turn consumed by another service and a stream processor such as Apache Flink, Kafka Streams, or Spark Streaming. Since this topic seeds the data stored in the other downstream topics and local data stores, it is the initial source of data that is shared between the first two consumers. A traditional queue would delete a message that was processed by a consumer, but in this case a message will still be available to other consumers since each such consumer keeps track of messages it has already read. And it is still available to the same consumer if the offset is reset to reflect a past point in time (e.g. in cases where the code for the consumer has been changed, and historical data needs to be replayed by this new code).
Conclusion
So is there any overlap between ShSOT and SSOD, SVOT, or SSOT? In some sense, parallels can be drawn between these concepts. However, traditional databases consist of static data from the standpoint of consumers. In other words, a database does not keep track of records which have been read per se with respect to the order in which records are to be read by consumers. In the above example, topic A can be seen as the SSOD for data elements which are propagated or used as input for additional processing downstream, but does it make sense to refer to SVOT or SSOT?
Probably not. If the same data element is represented with different versions within the same data stream, it is a matter of time until conflicts are resolved, due to elapsed time, although keep in mind that consumers may need to apply additional processing logic unrelated to transpired time. Data streams are often used to consume events which are essentially independent of one another (e.g. in the case of events representing simple forms of state etc), or distinct in nature from those found externally to them, so such conflicts will likely not come into play. In this sense, with the presumption that such data representing the same things is not being consumed from multiple sources, ShSOT is the same as SSOD.
That said, it’s probably best to refrain from using similar-sounding phrases across different technology domains. If you do, be prepared to explain. As I wrapped up with my earlier variations of this post, make sure you clarify what is meant by any expressions that you use so that opportunities for miscommunication are minimized.


