7 DevOps Patterns to Meet Today’s Cloud Challenges

Many standard DevOps patterns are well known at this point. Advances in technology, cloud computing, and workload orchestration in IT have heralded a new generation of DevOps engineer and tooling to meet modern business challenges. In this article, we will surface and give name to a few patterns as related to the emerging realm of pipelines as code, declarative deployments, multi-cloud, and more.
Ever-evolving: The world of DevOps
DevOps practitioners daily wade through vendors, terminology, platforms, cloud services, and nomenclature of an ever-shifting industry. DevOps encapsulates the idea of continual improvement and constant learning, so it is no surprise that patterns and practices that work well and those that do not surface pretty quickly. Some patterns that have proven to accelerate software delivery and improve product quality include:
- Build once, deploy many times
- Immutable infrastructure as code
- Eliminating outside dependencies
- Version control everything
- Well-defined git branching models
That which is old becomes new again. Or so they say. Many topics in this article are not new patterns but recycled ideas of things that have worked in this or other industries for quite a while.
What is a DevOps pattern?
For the sake of this discussion, a pattern is a solution or set of solutions working together with the goal of supporting or driving DevOps within an organization. Not all patterns are DevOps specific, and some may not even be considered DevOps best practice. Different requirements, team makeup, and organization culture usually demand different types of solution patterns.
Exploring pipeline complexity
I have now worked with multiple development teams to help layout their DevOps strategies and formulate solutions to execute them. The common element for all of these engagements has been that the amount of time to ramp up solutions was heavily dependent upon the pipeline complexity. I've put together an arbitrary complexity chart to help visualize how the complexity can quickly ramp up based on the additive requirements for the DevOps pipelines being created. From left to right, each defined task is additive upon the prior task, which increases the resulting pipeline complexity accordingly.
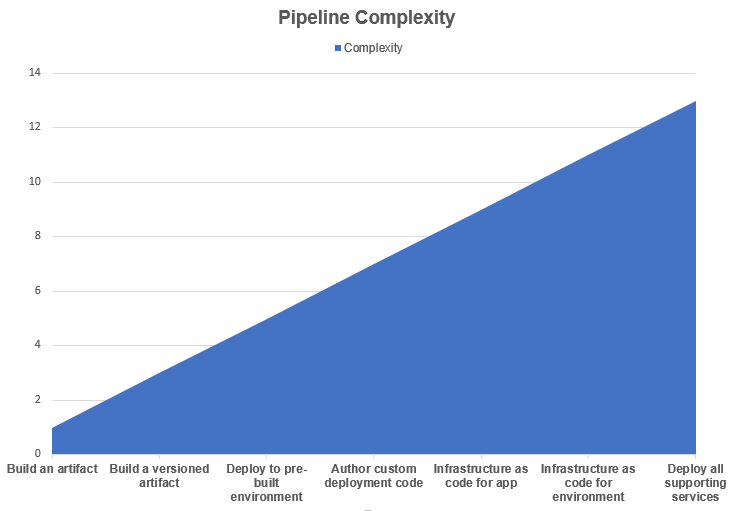
The listed tasks are realistically arbitrary. If your artifact is a bundle from multiple distinct repositories nestled in sub-folders of unique branches that need to be custom compiled and bundled with specific libraries and made to work with glue and prayers in a docker container that has to use an undocumented base image (gasp!), then creating the artifact may actually be the most complex part of a pipeline!
Pattern: Cradle infrastructure
This is when one deploys and configures a baseline environment using a separate process than the code being deployed into the environment. The base environment infrastructure essentially "cradles" the workload deployments. This division of work can be at multiple points within an infrastructure and can be nested multiple levels deep. There tends to be a natural split between the network/system operators and the developers wherein the operators will deploy and help operate any number of target environments as a platform for the developers to target with their code delivery pipelines.
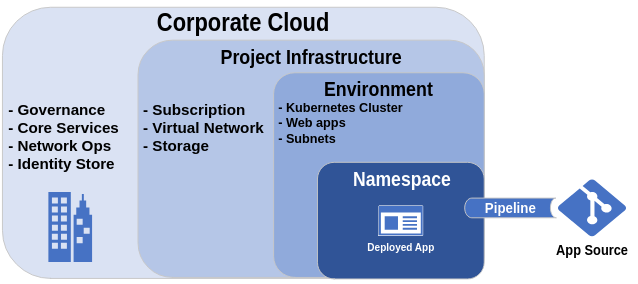
This should not be confused with the "split infrastructure" pattern.
Pattern: Split infrastructure
This pattern is similar to that of the Cradle Infrastructure in that it divides the total surface area for infrastructure deployment among multiple teams. The difference is that more responsibility for the infrastructure creation falls more to the DevOps pipelines. Essentially the baseline infrastructure is at a higher level wherein there may only be some general networks and policies configured as guidelines for further infrastructure as code to be deployed in downstream pipelines. Alongside the baseline infrastructure, privileged accounts will be delegated rights to further deploy within their cut of the organization's cloud or data center.
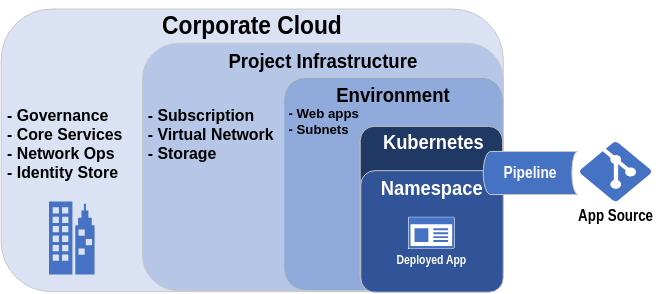
Careful planning and consideration on how the teams operate and how they collaborate should be done when designing a split infrastructure.
Pattern: OpsDev
This is the practice of allowing developers to operate and code directly against an environment infrastructure for a project. Often this is done to "get things working" in a development environment first, wherein a pipeline will later be crafted for further releases into other environments. In the OpsDev pattern, it is typical to see your developers using IDEs to connect to and deploy code right from their workstations into Kubernetes clusters or cloud services. A good deal of OpsDev tools are emerging to help skill up development efforts for cloud native computing against Kubernetes. This runs the gambit of feature/functionality.
This is not the same as using modern programming languages to allow developers to construct their own infrastructure as part of their deployment. Using Pulumi or SaltStack, or even using straight boto3 Python modules to build out any kind of infrastructure as real code is covered in the next pattern.
Pattern: Infrastructure as real code
This is when a "real" programming language like TypeScript, Python, or similar is used to define and construct the target deployment infrastructure in an imperative manner instead of via declarative manifests. Pulumi is the immediate example of a tool that allows for multiple real language bindings to be used that can be used to define and create the infrastructure. SaltStack would be considered another.
- In the right hands this can be a very powerful way to go from project ideation to reality very quickly
- This can, in theory, greatly simplify deployment pipelines
- A more highly specialized skill set is required to support the pipelines for such a deployment
- More room for abuse in practices if not carefully monitored (hard coded secrets or other parameters for instance)
- Very new way of doing things, as such it is technically less battle tested
Pattern: Pipeline independence
This is the practice of authoring pipeline as code to be run within the CI/CD platform first but in a way that it can also be run locally from a workstation. This enables additional lateral movement and options in the event that the pipeline platform is unavailable or needs to be changed out. This almost always requires additional effort to implement but doing this extra work allows for future flexibility and can force the pipeline authoring to be done in a more composable manner.
I like to call this "dual-pipelining" as, in some cases, can be double the amount of work to maintain!
Pattern: Declarative infrastructure as code
- This is a relatively common method of deploying immutable infrastructure and has been battle tested
- There are more rigid guidelines and rules in place around the language structure which can lead to fewer mistakes
- In the right hands this can also be a relatively quick way to go from project ideation to reality in a rapid manner
- You can maintain a consistent known state at all times by applying the declarative code base on a regular schedule
- The tightly defined rules can severely restrict or prevent keeping a DRY (Don't Repeat Yourself) code base
- You need to know all of your infrastructure elements and keep it maintained with a backend known state
- The declarative way of coding is often an operations team skill that require additional resources beyond the core development team to implement
- The code is driven by third party providers which can vary in quality
- The tightly defined rules can often lead to shortcuts being implemented which reduce the overall value of using declarative code to begin with
Pattern: ConfigOps
ConfigOps, like any *Ops, starts with a git repository. In that repository is a structured set of files or directories for configuration of a project that is then delivered via pipelines to seed and maintain configuration for other pipelines in the project.
ConfigOps can be done within the app source repository or can be done in an independent git repository. The net result is the same, an audit-able trail of changes for configuration elements used in your project pipelines.
What other patterns are there?
These are some patterns that I've noticed and feel should have terms of their own. Are there any other DevOps or related IT patterns that deserve their own name? Please feel free to contribute to the repo I've started to catalog devops patterns.
Ready for what's next?
Together, we can help you identify the challenges facing you right now and take the first steps to elevate your cloud environment.
