Azure Databricks for Data Science & Engineering Teams – Part 2

The analytics arm of a large midwestern U.S. insurance firm asked SPR to implement a pilot phase as a follow-up to an initial proof of concept (PoC) phase that SPR carried out during prior months. As discussed in part 1 of this two part series, the company had asked SPR to help by focusing on the portion of its architecture making use of Azure HDInsight, and building a PoC on Azure Databricks Unified Analytics Platform for the company's future state architecture.
While we took into account how Databricks usage might fit as part of the targeted production environment, production machine learning (ML) models and data workloads were not included in this initial effort due to their sensitive nature at the time. As such, following the conclusion of our work on the PoC phase, a separate pilot phase was carried out by SPR specifically to perform the following:
- Migration of 3 production ML models
- Migration of production data used by these models
- Recommendations based on what we saw during the pilot phase
Using these directives, we first built out the components used in the initial PoC using the firm's existing Azure accounts.
Background on Databricks Proof of Concept (PoC)
As discussed in part one of this two-part series, criteria for the PoC was threefold: (1) focus on the R language for ML models, (2) account for current data science team development processes, and (3) preference for use of Azure Data Factory for data pipelines, which the current data engineering was already looking to adopt.
As part of the PoC work, SPR assessed products associated with Databricks and the broader Azure ecosystem, and determined that some were either not production-ready or not fit for the use-case. For example, while MLflow appeared to be a promising open-source framework (created by Databricks) to standardize the end-to-end ML life cycle, it was also in alpha, and R language support had been recently added. Additionally, while we successfully set up Visual Studio 2017 to remotely connect to a Microsoft Machine Learning Server instance via Microsoft R Client, we did not recommend use of this tooling.
After building the PoC, we broke down our work into 12 tasks categorized into DevOps and data pipeline. Components included Azure Databricks, Azure Blob Storage, Azure Data Factory, RStudio Server, Azure DevOps, R, Python, Databricks CLI, PowerShell, RStudio Desktop, and Git.

Databricks Pilot
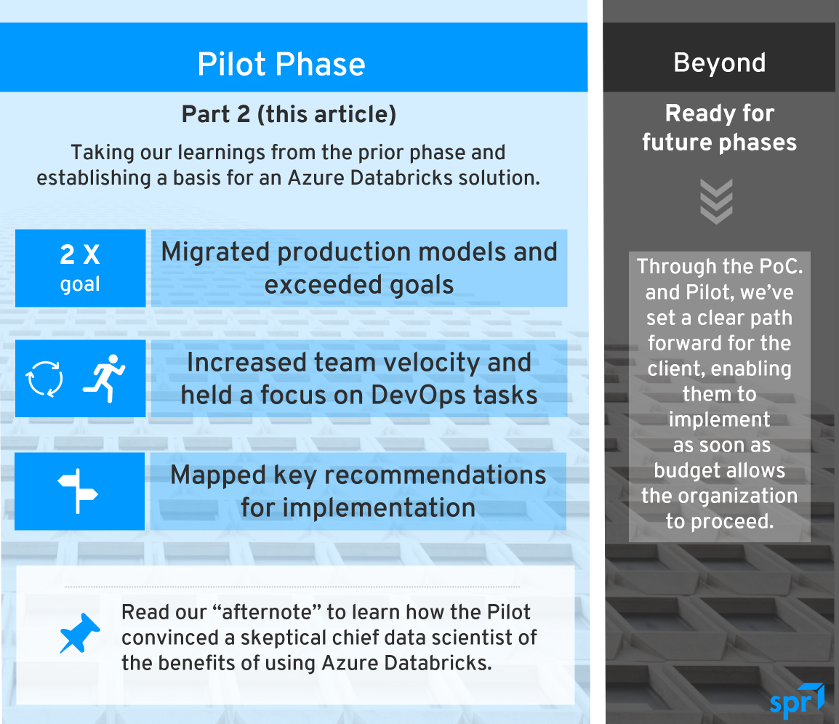
We migrated a total of six production ML models (twice as many as the initial goal) from HDInsight to Databricks, along with the production data used by these models. All of these models were intended to predict the level of expected consumer adoption of various insurance products, with some having been migrated from SAS a few years prior, at which time the company moved to making use of HDInsight.
For the first three models, we used a strategy to migrate an easier model followed by models of increasing complexity. The goal was to work out basic migration details before progressing to models that depended on those details. We encountered 14 specific technical implementation issues and resolved or implemented workarounds for all; because all issues were encountered and surmounted during our work on the first three models, team velocity significantly increased for the latter three models.
Key challenges were categorized into four areas:
- Poor data quality (biggest challenge)
- Lack of comprehensive versioning
- Tribal knowledge and incomplete documentation
- Immature Databricks documentation and support with respect to R usage
To address these challenges, we made recommendations in five key areas as a follow-up to our implementation work:
- Big picture view
- Automation
- Configuration and versioning
- Separation of data concerns
- Documentation
Since client data, platform, and modeling teams were associated with each model, solution approach and analysis and issue resolution needed to be performed across all three teams. It’s common within large organizations for silos to form, so it was especially critical for the teams to be in sync with respect to data platform usage. As such, we advised these teams to collaborate and align using their existing architecture group.
While work on continuous integration and delivery (CI/CD) automation had started, a majority of what was built was limited to work performed across the teams. As such, we advised that end-to-end pipelines be built across artifacts managed by each team. During our model migration work, we saw firsthand the mistakes that lack of automation was causing, and how manual steps were resulting in added cost.
To fully enable automation, reduce errors and support repeatable builds and deployments, we recommended wholesale configuration and versioning as a separate task. This helps support consistent results every time; it allows all table schemas, reference data, and R packages used by models to be versioned as one unit within the context of each model. Additionally, hard coded values that are pervasive in the code base can be converted to easily maintained configurations.
Code deployed as models contained content that was not constrained to the actual models, so we advised data be managed separately. This increases visibility of data work and prevents more complexity and ripple effect in the code base.
Lastly, we recommended centralizing current documentation and making it more comprehensive. Doing so makes documentation easier to maintain and allows members to be added to the data, platform and modeling teams more quickly.
The pilot implementations of Databricks we built included all technologies listed previously except for Azure Data Factory; rather than focus on data pipeline tasks, DevOps tasks remained our focus for the duration of the pilot phase. That said, we did put together a high-level architecture document to provide insight on how a data pipeline might be tackled post pilot phase. In addition to the aforementioned components, which included two subcomponents of Azure DevOps (Azure DevOps Repos and Azure DevOps Pipelines), Databricks and MLflow were also included in this architecture.
Databricks Connect permits connections from notebook servers and IDEs (integrated development environments) to Databricks clusters to run Spark code; we did not release this until after the PoC phase concluded, during which it was in private preview. The status of MLflow, mentioned earlier, progressed to beta during the pilot phase, and was made available as a managed service called Managed MLflow during the concluding weeks of the pilot phase. As momentum began to build around this framework, we wanted to share how it could fit in with the rest of the architecture.
The Result
In addition to migrating six models—twice as many as the initial goal—and the associated data used by these models from Apache Hive to Spark SQL, we also delivered dozens of annotated Databricks notebooks developed using PySpark and SparkR cluster initialization ("init") scripts; we wrote these to be executed on Databricks cluster startup, and included detailed documentation explaining our work, how to perform it, and the recommendations outlined above.
While the PoC and pilot phases of our work were both successfully executed, subsequent work was not performed due to client budget. That said, our work on these two phases convinced a very skeptical chief data scientist that Databricks was a winner. During our final presentation, he indicated to project stakeholders that their next goal would be to migrate remaining models to Databricks as quickly as possible!
Afternote: So Why Databricks?
Below is a brief survey of factors that led our client to move from skepticism to adoption.
Databricks just works
At the outset, the client stated they already tried Databricks it didn't work out. Databricks hadn't been made generally available in Azure until recent months, so the question was, to what extent had they worked with the product? It turned out, the staff lacked needed skill sets and didn't have the necessary bandwidth to pick these up. Our team was brought on board to address this roadblock.
The first client directive for the pilot phase was to migrate a subset of ML models with no changes to the original code. One of the primary reasons for not changing the code was to prevent downstream effects from introducing change to the code base. The only programmatic changes we ended up needing to make were to address data quality issues, some due to migrating from Apache Hive to Spark SQL as part of the process.
We rigorously compared model output from HDInsight and Databricks for full production datasets, and found only one output value of dozens which differed, affecting the latter three models we migrated. In reviewing these differences with the client, it was determined that these were due to changes to Spark function "percentile_approx" over time, as the versions of Spark used by HDInsight and Spark were different.
Note that we used a relative tolerance of 0.000000001 when comparing model output, and when adjusting for more tolerance the differences for this sole column disappeared. Regardless, the minor deviance experienced was considered immaterial by the client.
No needed changes to library packaging
While this second part of the case study mentions that we encountered and surmounted 14 specific technical implementation issues during the pilot phase, keep in mind that we had already become familiar with Databricks by building a PoC; during that time we also addressed specific client obstacles associated with their initial trial runs in prior months.
One of the remaining stumbling blocks for the client team had been the ability to install proprietary R packages that they had developed, in contrast with R packages made publicly available via CRAN (Comprehensive R Archive Network). After demonstrating how to do so via notebooks, we also advised to move installations of all needed R packages to Databricks cluster initialization ("init") scripts so that these would be available to all cluster nodes used by executing models.
Integration with chosen Git implementation
Databricks did not initially offer out-of-the-box support to specifically address integration with Azure DevOps, a product which also had just recently become generally available. But this lack of support was really a limitation of the notebook user interface, which offered minimal explicit support for Git compatible products.
Since we did not want any unneeded user interface dependencies, we first showed the client team how to programmatically integrate with Azure DevOps, and later also implemented automated syncing of notebooks to Git. This would minimize the need for developers to do so while programming, and also store all code in the same centralized location being used by client teams.
Notebook alternative exists
While the client made it clear that modelers on their team used a variety of development tooling, they also made it clear that they were highly averse to using notebooks. While notebooks have quickly become widely popular for data science in recent years, they were accustomed to programming via command line and an IDE called RStudio Desktop, and did not like the idea of being constrained to using notebooks for development, as they felt some scenarios (such as for debugging) were a bit challenging.
Our solution made use of RStudio Server, the installation of which we included in our cluster initialization ("init") scripts, to provide the option to make use of a browser based version of RStudio Desktop. Also, since the Azure implementation (unlike the AWS implementation) of Databricks does not permit SSH to clusters, RStudio Server additionally provided command line access similarly to RStudio Desktop.
And, as the notebooks that we developed intermingled Python to execute pipeline code, R to execute models, and SQL for exploratory work, by the end of the pilot phase client teams began to see this as an advantageous feature.
Hadoop goes away
Reiterating this content should be considered only as an afternote, several challenges were either expressed by client teams or experienced by my team during our migration work from HDInsight to Databricks. As we needed to compare data output from models executed in HDInsight and Databricks, this required us to execute first on HDInsight, which meant we needed to make use of Apache Hadoop YARN for resource management and job scheduling and monitoring.
The HDInsight cluster was being launched at the beginning of the day and taken down at the end of the day, and Hadoop processes were sometimes unavailable, preventing the ability to resume our testing. When this issue did not surface, we were still concerned with configuration—the improper setting of which resulted in obscure error messages.
After migrating the first model, the client was happy they didn’t need to fiddle with YARN. Databricks is not built on Hadoop, and does not have the legacy constraints of Hadoop. And, since it had taken hours each day to bring up the HDInsight cluster used by client teams, bringing up Databricks clusters on an as-needed basis was seen to be a significant benefit.
Since the client’s focus was on the Apache Spark component of Hadoop, we weren’t encumbered with unnecessary legacy constraints, not to mention the much wider available selection of Databricks cluster node configurations.
To learn more about Azure Databricks or other options within the Azure ecosystem or to discuss how your business could benefit from machine learning models, please contact us.
Ready for what's next?
Together, we can help you identify the challenges facing you right now and take the first steps to elevate your cloud environment.