How to Mentor a Data Engineering Team while Running

A top 10 (U.S.) grocer client contacted SPR to help them with their data lake. While we typically implement such solutions from scratch for our clients, the non-U.S. division of this client had already put a solution in place, and the U.S. division was dependent on this same infrastructure. The company was looking for recommendations, mentorship and training, and a build-out of the first iterations of their data lake. This technical case study will walk through the challenges and how we solved them for the client.
Background on the client
One significant constraint was the client’s need to use existing CDH 5.15.x (Cloudera Distribution Including Apache Hadoop) clusters already in use by the non-U.S. division.
Additionally, not only did U.S. data need to be kept separate from non-U.S. data, data pipelines and DevOps pipelines also needed to be kept separate, with little visibility provided across the two. To help enable cross-team collaboration, we also needed to largely remain within the subset of Hadoop ecosystem components being used by the non-U.S. team, with recommendations of alternative tooling, technologies, and processes kept as separate sets of deliverables.
While our client had long-term goals for recommendations, mentorship and training, they also needed to start building out their data lake right away. We recommended that since the data engineering team needed working code, why not choose use cases that addressed real business needs? This way, we could tackle both goals at the same time.
Background on the Hadoop ecosystem
First, we needed to explain “Hadoop” to stakeholders to make sure everyone was on the same page. As explained by the Apache Hadoop project, Hadoop is an open source framework that permits distributed processing of large data sets across clusters of servers using simple programming models. These are designed to scale up from single servers to thousands of machines, each offering local computation and storage. They also are designed to detect and handle failures at the application layer rather than relying on hardware to deliver high availability. However, notice all of the related components. These components are deployed to the same machines used by Hadoop, working together to form what is commonly referred to as the Hadoop “ecosystem.” All of this was to help everyone get on the same page when someone refers to “bringing data into Hadoop.”
The diagram shows a very high-level representation of what this looks like for a use case involving ingestion of data from a source database, and consumption of data by visualization / reporting. The large light gray box is intended to represent a single cluster node, but since a cluster contains multiple nodes, and components are distributed across all of these, with a single node not being used for all components in every case, this is a very simplified representation to show how components relate to each other with respect to integration.
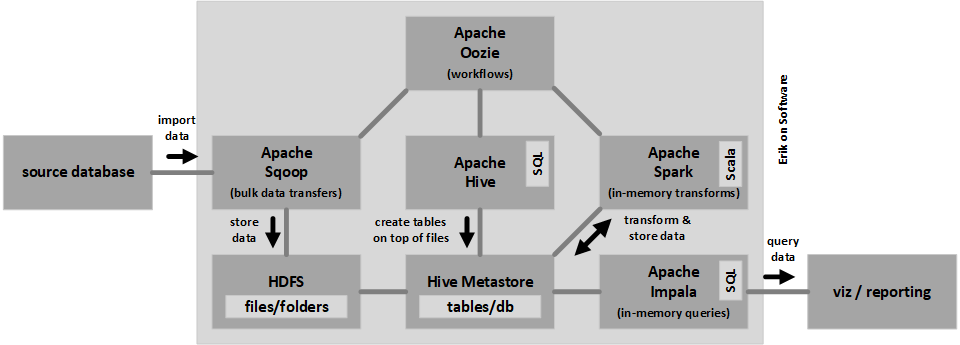
It’s also important to pay attention to component versions. The developer community tends to generically reference components, and component versions can significantly affect feature availability and maturity.
While it is accurate to say commercial distributions of Hadoop help manage version compatibility across components, this management does not negate the need for development teams to understand the capabilities of each. See the table below for a listing of several of these components. The versions of Apache Spark and Apache Hive already being used, for example, were particularly important.
Note that the component versions listed here are in many cases not identical to their open source equivalents, even though version numbers are the same. Cloudera tends to bundle select bug fixes from later releases but leave the version number static, except for a CDH specific extension that is not included in this table.
| Component | Open Source Version | ||
| CDH 5.15.x | CDH 6.3.x | Latest | |
| Apache Hadoop (includes HDFS, MapReduce etc) | 2.6.0 | 3.0.0 | 3.3.0 |
| Apache Hive | 1.1.0 | 2.1.1 | 3.1.2 |
| Apache Impala | 2.12.0 | 3.2.0 | 3.4.0 |
| Apache Oozie | 4.1.0 | 5.1.0 | 5.2.0 |
| Apache Parquet | 1.5.0 | 1.9.0 | 1.11.1 |
| Apache Spark | 1.6.0 (2.4.0) | 2.4.0 | 3.0.1 |
| Apache Sqoop | 1.4.6 | 1.4.7 | 1.4.7 |
We initially presumed use of Apache Spark 1.6.0 at the start of this engagement due to their CDH 5.15.x installation. This version of Spark is particularly old, first released in January 2016. Fortunately, Apache Spark 2.4.0 had been installed by our client due to availability of the Cloudera support they desired (the reason this version is listed in parentheses). While this newer version is still 2 years old, it provides greater features and maturity to enable eventual use of other libraries and frameworks which depend on it, such as open source Delta Lake.
Prior to starting our project together, the client had planned to move to CDH 6.3.x. But as can be seen in the table, some components have evolved faster than others. Some, such as Apache Sqoop, exhibit an especially high level of inactivity in terms of community releases.
So how do you know whether a given open source component or library is a good candidate for adoption? We tell our clients to gauge how much developer community activity is around it. Since many firms have moved away from Hadoop, instead focusing on Spark, other open source components not intended for deployment to Hadoop clusters have since been made available to make up for this gap. The low activity around components such as Sqoop and Oozie, combined with the high number of bugs we needed to work around during this engagement, points to industry moving elsewhere.
Data lake build-out, mentorship & training
The bulk of our time on this engagement was spent building out the first iterations of the data lake. As mentioned previously, the work was communicated as a short-term tactical need, but as we were also tasked to enable the data engineering team, we recommended the build-out be used as a catalyst to do so. We used a real business use case for the implementation: a use case for their logistics department.
The first step to implement this use case was to understand what was needed. For example, we reviewed all the SQL queries being executed against source databases, as well as the data itself. At the same time, we also implemented HDFS folder structures and Hive Metastore databases along with security and permissions. We then built and tested data pipelines to ingest applicable source data into what our client referred to as the “landing”, “discovery”, and “shared” stages (or layers) of data in the data lake. A sidebar of an earlier case study explains commonly used data stages in industry.
The name of this third stage of data was a misnomer because it was actually related to denormalized data rather than security. But we continued to use these names to ensure collaboration between the U.S. and non-U.S. teams. We then walked the development team through steps related to denormalization, focusing on current and potential future needs.
This third stage of data is where use case solutions are no longer generic, instead focusing on the data specific to each business domain. We demonstrated a step-by-step approach to execute this process, using pertinent logistics department data.
After getting familiar with current and potential future data needs, we rewrote current state exploratory SQL Server queries for Impala while also getting familiar with the source data read by these queries, and tested these with data ingested into the discovery stage, following up by designing denormalized tables where needed with a focus on performance. Along the way, we explained important practices to follow so that the data engineering team would be able to continue to evolve the data lake following our departure.
While data quality is mentioned in the key current state observations and recommendations below, one additional thing worth pointing out here is that we became aware of the state of data quality in source database tables during our execution of hundreds of exploratory queries against source databases.
We discovered, for example, that some source data records were being physically deleted, and some fields were not being consistently populated. In addition, many source database tables made use of natural keys rather than surrogate keys, and we explained the implications with respect to the data lake. We recommended both how to resolve these issues in source applications and how to address these issues during the data cleansing process.
Key current state observations & recommendations
SPR initially delivered 33 sets of observations and recommendations in 10 key areas:
Low-level:
- code
- data stages (layers)
- accuracy
- quality
- performance
High-level:
- infrastructure
- security / permissions
- development process
- governance
- documentation
As the U.S. division of our client had not performed any development prior to our team joining, observations and recommendations were largely made for what the non-U.S. division had already built out, although some high-level areas not specific to build-out (such as development process) also pertained to the U.S. division.
Low-level
While the above lists are generally not ordered in terms of importance or frequency of occurrence, code is intentionally placed in the first position here because it overlaps with so many other areas, much like the case with infrastructure.
Artifacts should be versioned via code in source control. Everything should be versioned, and versioning implies code. Doing so enables consistency with deployments, the ability to track changes as a cohesive unit, and the ability of developers to independently develop and test different versions of artifacts in parallel with each other.
While exploring both formal data lake environments and version control, we noticed that some deployed object definitions, visualization / report definitions, and data pipeline code did not exist in version control. We also saw inconsistent use of formatting in the code, oftentimes making it challenging to read, and so additionally recommended artifact consistency.
For some artifact types, we relayed recommendations specifically based on community documentation. For example, since Impala stores SQL statements in lowercase, it makes sense to write this code using lowercase, so we included this step as part of the tuning process (recommendations for SQL Server code were also provided).
We provided the most observations and recommendations around the stages they made use of in their data lake. While it appeared that our client had initially followed some level of consistency, in working through what was deployed it was often challenging to determine where data should be obtained given a particular need. For example, views in lower stages of data sometimes referenced higher stages, and the presumption was that when views in one stage reference tables in another stage, the direction of these references should only be down, not up.
Denormalized tables and aggregates existed in the discovery stage rather than the shared stage, and the shared stage itself seemed misnamed, seemingly implying that it was related to security rather than denormalization. Additionally, we recommended that the landing stage for raw data solely make use of string data type and partitions for load date only, excluding attempts at use case specific performance improvement. As with traditional software development, we advised our client to resist the urge to preemptively optimize.
With respect to accuracy and quality, we noticed considerable amounts of on-the-fly data cleansing taking place in the code. As such, we recommended preemptively cleansing data in some cases in order to increase performance and decrease complexity of queries. Additionally, we noticed inappropriate data types being used in downstream data stages. For example, some data engineers made use of the double data type for numeric fields used in Impala aggregates. Because doing so can result in inconsistent aggregate calculations for visualizations / reports, we relayed the Impala project recommendation to instead make use of the decimal data type.
We also provided a high number of observations and recommendations around performance. Our first recommendation was to explicitly gather statistics following data loads to Impala, and the non-US team immediately added this step to their data pipelines so that they could start taking advantage of this improvement. Gathering statistics ensures metadata accuracy for SQL queries, which can significantly affect performance, so doing so is one of the first tuning steps that should be followed, as is the case with traditional database products.
As mentioned earlier, we recommended consistent use of the string data type in the landing stage. Apart from this stage being used for raw data, use of string data type here also enables better performance for writes just like use of parquet data type enables better performance for reads. We also noticed that some partition definitions might significantly exceed recommended Impala limits, so we relayed documentation for this aspect as well, noting that the cardinality of stored data values is used during the partition creation process.
High-level
From a high-level perspective, we provided the most observations and recommendations around infrastructure. For example, our client was making use of on premises, fixed count CDH clusters. We recommended that the firm consider use of the cloud for their Hadoop ecosystem, which would enable scalability and on-demand creation, as well as separate clusters for US and non-US divisions since cross-team data access was not being permitted anyway.
That said, Hadoop has largely fallen by the wayside in recent years, at least in terms of the batch processing provided by MapReduce, in favor of a focus on in-memory Spark and other technologies typically decoupled from what has increasingly been viewed as a heavyweight, challenging-to-manage ecosystem. We have migrated analytic workloads away from Hadoop in the past, and a preceding focus on Spark greatly enables such moves because the code becomes largely portable, enabling standalone use of Spark, although the challenge then shifts to replacing the greater ecosystem still tied to Hadoop, and ensuring that data engineers have the skills to write Scala or Python code for Spark.
A related recommendation we provided was to additionally make use of a sandbox environment that can be used for developer experimentation to help ensure stability for the separate dev environment that was serving a dual purpose as a sandbox.
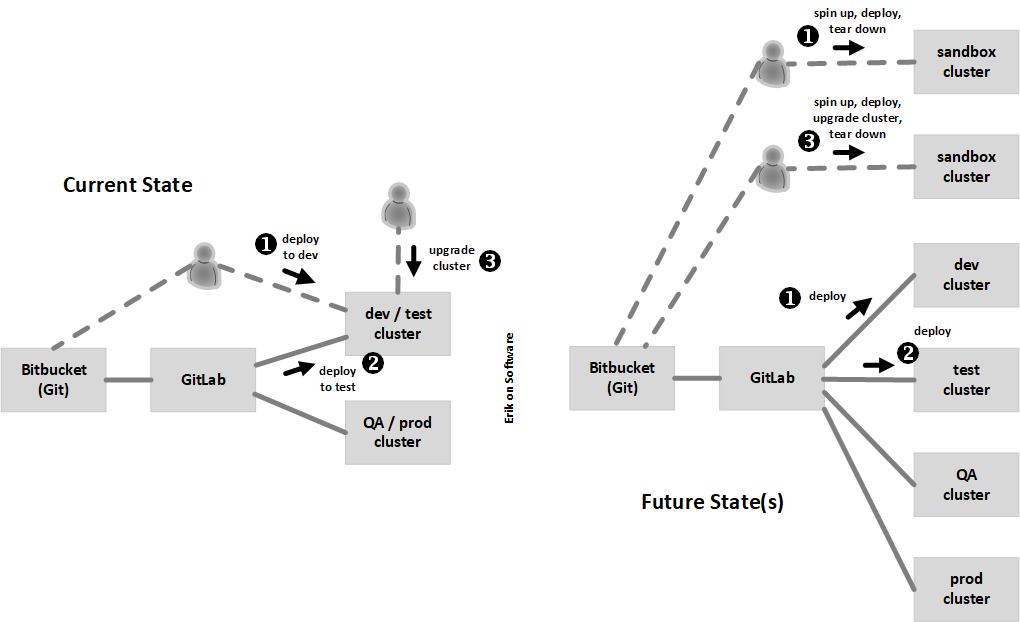
During our last weeks of this engagement, we also discovered that an upgrade to CDH 6.3.3 was being performed for the first time to the dev / test cluster, rather than first being tested out in a separate upstream environment to help ensure successful upgrades of formal environments. We explained that the difference between a sandbox and dev environment is that the latter should not contain any manually deployed artifacts. Developer testing should be performed in a stable environment prior to being deployed to the test environment, and reaching a state of stability implies that a duplicate environment can be created solely from what is stored in version control.
The nearby diagram on the left below illustrates the contention that can exist, with (1) the data engineering team looking to deploy to the dev environment, (2) the infrastructure team looking to upgrade the cluster for this same environment, and (3) GitLab deploying to the test environment residing on this same cluster. All of these activities make for both an unstable environment, as well as potential delays.
Turning focus to the right, best practices instead permit the spinning up and tearing down of on-demand, standalone environments for deployment and testing that does not affect other activity, and all formally managed environments involve no manual deployment, ensuring consistency. Lastly, the activities of the infrastructure team are absorbed by the data engineering team, resulting in the intended merger of development and operations for DevOps.
We also recommended that syncing time across cluster nodes and edge nodes be implemented, as it can be challenging to follow logs for some components, as well as enabling the Python interpreter for Apache Zeppelin. While we understood that our client largely standardized on Scala and R, we also expect that many new developers will be looking to use Python since it is currently the most used data science and data engineering language. Partially because our client installed Spark 2.4.0 and no longer made use of Spark 1.6.0, we also recommended considering use of Python 3 because Python 2 is a deprecated language version no longer supported by the Python Software Foundation, even though Spark 2.4.0 supports both.
An important infrastructure piece is security / permissions, around which we presented several high-level observations and recommendations. For example, we noticed that piecemeal, manual changes were being performed, and we recommended our client instead incorporate these as part of DevOps to ensure a repeatable process. This adds visibility when everything is included as code in version control. We also recommended that local laptop development environment restrictions be lifted for developers to ensure access is available for any needed development resources, such as Maven repositories for Scala builds, in a timely manner.
Lastly, we presented observations and recommendations around development process, governance, and documentation. Based on what we saw during our engagement, we recommended itemizing what is needed to onboard new developers over time to help ensure that they can get up to speed in a timely manner, adopting a lightweight process framework such as Scrum or other, and releasing on a fixed, relatively frequent schedule coinciding with each development time period.
With respect to governance, we recommended that consistency enforced version control pull request reviews continue to be followed, that some lightweight structure for architecture and development be created in lieu of an enterprise architecture team, and that efforts such as environment upgrades be coordinated across teams, pointing back to our earlier recommendation about using a sandbox environment.
The result
We developed and deployed a new data lake for both a logistics use case and other minor marketing use cases. This included all associated data, data pipelines, DevOps pipelines, and documentation of what was implemented, as well as observations and recommendations, tuning and denormalization guidance, Git guidance, and long-term strategic guidance.
Technologies used during this effort included CDH (Cloudera Distribution Including Apache Hadoop), Apache Hive, Apache Impala, Apache Oozie, Apache Parquet, Apache Spark, Apache Sqoop, Microsoft SQL Server, Scala, SQL, Linux Shell, Eclipse, Maven, Bitbucket (Git), Visual Studio Code. Our client was in the midst of migrating from Jenkins to GitLab at the time.