Managed Kuberentes services allow you to dive into Kubernetes quickly. But even a managed kubernetes cluster requires more thought and care than one may expect.
Introduction
Before kubernetes burst into the scene like Kramer in a Seinfeld rerun we were all happily running managed containers in Azure’s ACS, Amazon’s ECS/Fargate, or maybe even using Docker on some virtual machines. This was good enough for most enterprises if they decided to run anything in containers at all of course. But the deployments for such containers were fundamentally flawed in that they were tightly bound by the cloud provider running the services you were deploying against. To some extent Docker (compose) bridged some of this cloud gap. This container abstraction only helped at the developer workstation level though. Orchestration beyond the dev workstation meant dancing with a cloud vendor and their tooling of choice. This may explain things like ecs-cli, pre-kubernetes Rancher, and the explosion of DevOps as a popular IT career choice. All joking aside, Kubernetes has seen explosive growth partially because it helps abstract the cloud out of the deployment pipelines for businesses. It is exciting for IT veterans like myself as I can start to worry less about the underlying infrastructure and more about the workloads and their life-cycles instead. Unfortunately, Kuberentes still is infrastructure and running it is not like spinning up another golden image VM in your data-center (yet). So the cloud vendors have come to our rescue again but this time with managed Kubernetes services.
Production Grade
It is important to level set on the component parts of a production grade Kubernetes cluster. The term ‘production grade’ is key here because many local Kubernetes implementations you may deploy to test the waters (minikube, k3s, et cetera) do do anything for production level high availability. A quick rundown of the cluster component parts is in order. At its core, a cluster is actually two distinct planes running on servers (called ‘nodes’).
- Worker Plane
- Control Plane
The worker plane is where your workloads get scheduled and pods actually run. A default cluster deployment will have dedicated nodes for this plane but it is possible (though not recommended) to untaint your control plane nodes to allow for workload scheduling on your control plane nodes as well. The control plane is significantly more involved. It will contain, at the very least;
- kube-api-server - The control center
- Configuration store - etcd cluster in most deployments
- kube-scheduler - Pod placement
- kube-controller-manager - Your state machine
NOTE: Many diagrams also include a fifth component which was introduced in v1.6 called the cloud-controller-manager that can allow for easier cloud-specific integrations within a cluster.
For a primer on what the control plane consists of reading over
the official components documentation would be your best bet but here is an obligatory diagram anyway;
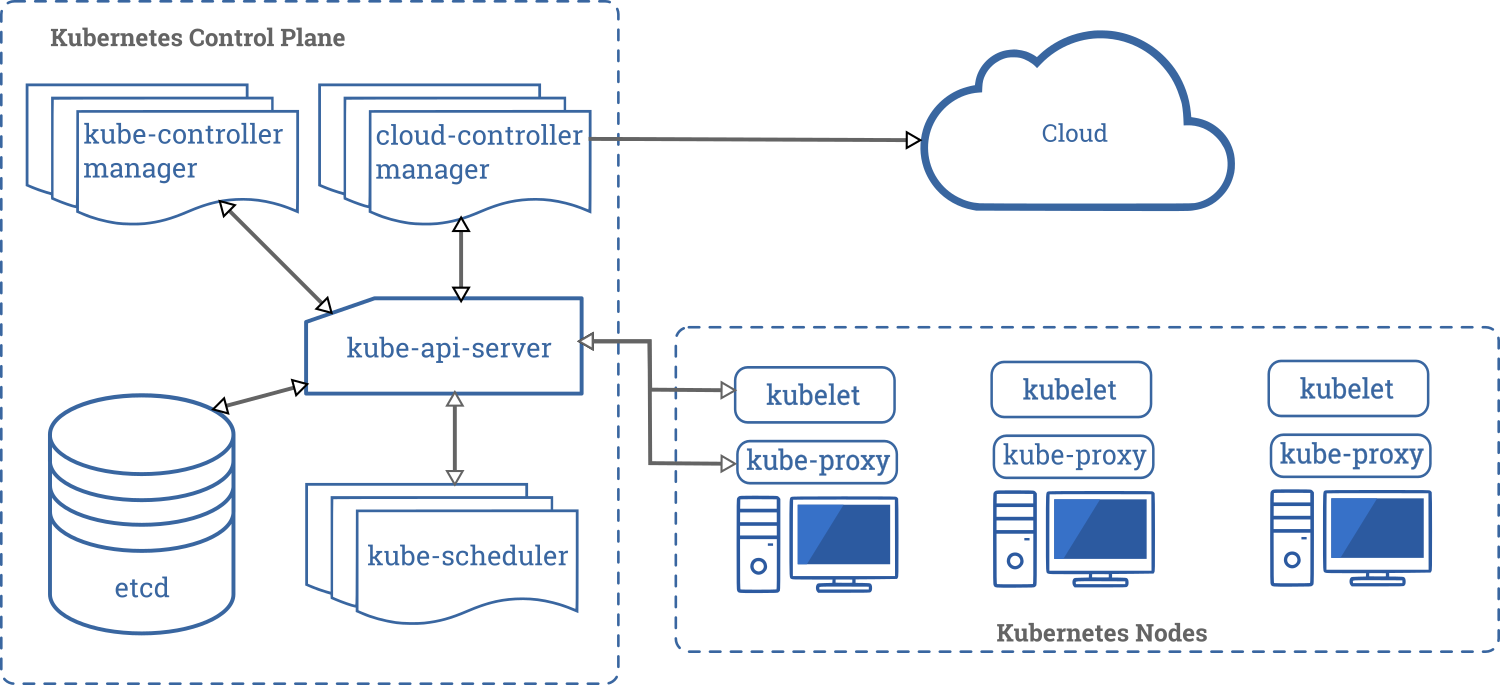
To be ‘production grade’, the control plane components should run across at least 3 nodes for high availability, be updated regularly, be monitored, and generally be loved like the rest of your infrastructure.
What Managed Gets Ya
Managed in IT is a contextual term as it holds different meaning based on the person you are talking with. A developer may read it to mean that the operations team manages it. In this light, a dev may then assume that a cloud managed kubernetes cluster is upgraded, patched, rebooted, or generally cared for transparently by the vendor. Yeah, that’s not what managed really means in this case, but here is what managed does get ya.
Invisible Control Plane
This is the first but most important aspect of managed kubernetes one must know. On a managed kubernetes cluster you are freed from the burden of the control plane. That’s right In a managed kubernetes cluster
the entire control plane is managed. This means the you can forego the 3-node initial requirement for your cluster and still have some level of HA for the back-end components. This alone eliminates much operational burden and is why I’ll go managed almost every time. This also means that if you had any designs to use the cluster etcd implementation for other means then you will have to deploy and manage this component separately.
Takeaway: Not having a control plane is awesome. It also means you simply don’t have that control you otherwise may have had.
Frosting On Your Cake
Deploying a kubernetes cluster from scratch for the first time only to realize you are unable to carve out persistent volumes or expose services via ingress feels like getting a brand new car without wheels. Cloud managed clusters provide their own solutions for these essential services to overcome this initial shortcomings. These are, as one might expect, targeted specifically to the cloud provider and usually involves consuming more of their own brand of cloud. The most important integrations in this space that ease operational burden incredibly are;
- Loadbalancer provisioning
- Storage provisioning (both block and file based)
This is exceptionally useful and an enormous time saver but there are, as one may expect, some precautions you should take.
Loadbalancers
Most loadbalancers create a public IP by default within the cloud. This is insecure and scary for all the reasons you think it would be. The general method to override this at deployment time is with a special annotation
service.beta.kubernetes.io/<azure/aws/google>-load-balancer-internal: "true". Also, you should question how much a load balancer is really needed for a particular workload. A load balancer is going to be largely required for non-standard traffic workloads like databases, DNS, or any other non-http type of traffic. For everything else there is ingress. In most deployments I’d expect no more than a single load balancer which is tied to your ingress controller of choice. At most you may have one ingress controller/loadbalancer per-zone for some stricter segmentation.
Persistent Volumes
Persistent volumes that tie into cloud storage have all the billing considerations to consider. Plus they may not always be suited for your particular workloads. If you have exceptionally heavy IO to disk then keeping a distributed local disk storage solution may be a consideration. It is also important to be aware that many Kubernetes deployments that I’ve done required specific tinkering around the cloud provider storage. This means you may find that your carefully crafted deployments are not all that portable in the end. Getting locked into a cloud provider for using Kubernetes should be considered an anti-pattern. Consider abstracting your storage presentation via something like OpenEBS if this kind of thing matters to you at all. You also have to consider just how many persistent volumes you will require. Some cloud providers have strict limits on the number of volumes that can be presented to each server node based on model.
Takeaway: Just because its easy to use, doesn’t mean you should use alot of it without thought. Loadbalancers and storage in the cloud have cost and security implications.
Kubernetes Upgrades
Managed kubernetes offerings should provide some form of upgrade path for the version of Kubernetes on your cluster. This is both a blessing and a burden. It is a blessing as upgrading Kubernetes is typically an involved process and this automation can allow you to seamlessly do rolling updates. It is a burden as the cloud providers will attempt to keep up with the rapid clip that Kuberentes is getting released and often stop supporting older versions from being deployed to new clusters. If you deploy your clusters via terraform and have pinned versions you may find that a manifest that once worked without issues suddenly fail, especially if you are not rebuilding your clusters frequently.
Takeaway: Treat your kube clusters as cattle and not pets. Redeploy them often to suss out issues that upgrades may cause your deployments.
Typically each cloud provider has some extra sauce features for further integration with their platform which can be enabled as part of the install or with some minor effort afterwards. This includes;
- Multiple node groups/pools
- Additional addons for dashboard or log integration
- Integrated authentication between the cluster and cloud resources
- Serverless virtual node pools for bursting workloads
- And so on…
What Is Left to You
I’m fully on the managed Kubernetes cluster bandwagon (regardless of the cloud platform). But there are some aspects of these managed offerings that should be on your radar. Here are just a few worth mentioning.
Node OS Updates
The cluster nodes are still running on an OS, one which needs to get updated and be rebooted like all others you have ever administered. If you are rebuilding your clusters frequently enough then this likely isn’t a huge issue. But let’s be honest, you know you aren’t rebuilding them are you? What’s more, I’ve personally seen nodes come online pretty much instantly requiring a reboot. And unless you login to your nodes you may never be the wiser. One tool you can use to help figure out what’s going on in regards to reboots is
kured made by the fine folk over at Weaveworks. If you do use this tool (and you should) know that the default behavior is for it to automatically reboot the nodes. This may not be your idea of fun if you have less than durable workloads running (for instance, spark streaming jobs). You can deploy kured so that it emits metrics with the reboot status and not take action though. In fact, simply collecting the metric prevents the daemon from initiating reboots. So, assuming you have prometheus already running on your cluster, you will need to deploy kured to feed its metrics into it (via a servicemonitor) and also point it to scrape prometheus to check for its metrics. Here is a generic helmfile with how I deployed this particular app to do just that. Obviously, make changes as required. https://gist.github.com/zloeber/bb27192fc1d35a7165366a81c7384ac1 And the query for your prometheus alerts that allow you to see which nodes require a reboot https://gist.github.com/zloeber/80453b3ce0630ab5851e492eb463d52a
Your Cluster Is Not All Yours
When you get your managed cluster up and running, one may expect to get the sum value of all the RAM and CPU of your nodes to use in your workloads. Nope. Sorry, you don’t get all of it. In fact, this is true of pretty much any cluster, managed or otherwise. Kubernetes is not an OS (as much as I so very want it to be). It runs on top of an OS, which immediately gets its share of the resources right off the top. Even worker-only nodes need to run some workload to be useful (mainly networking stuff) to there is more consumed. When we get into the next section this will make more sense but any ‘real’ Kuberentes cluster you deploy will also have a slew of related base services that will need to be running. These also gobble up some of the pool of resources in the cluster.
Takeaway: My rule of thumb is to assume about 25-30% of the overall cluster resources are simply not available and set my upper bounds on autoscaling node pools appropriately.
Making it Useful
If you create a new managed cluster in your cloud of choice, login to it via kubectrl and list out all the pods across all namespaces it is usually pretty underwhelming. This is because, like a desktop without software, you are only setup with the potential to do great things. It is still up to the intrepid admin to layer in the software and make the cluster worth a damn. This one may seem obvious. But it is not quite as obvious just how many layers of technology are required to stack into your cluster to make the thing useful. Here is an example of a stack of technologies that may make it into your cluster.
| Stack | Purpose |
|---|
| Fluentbit | Log Scraping and Forwarding |
| Prometheus Operator | Prometheus & AlertManager CRDs |
| Kube Prometheus | Kubernetes default service monitors and alerts |
| Prometheus Adapter | Custom Metrics Autoscaling |
| Heapster | Kubernetes Cluster Metrics |
| Dashboard | Admin Dashboard |
| Kured | Host Node Autoreboot |
| RBAC Manager | CRDs for RBAC |
| Cert-Manager | Certificate Generation |
| Traefik | Ingress Controller |
| Grafana | Metric Dashboards |
| IAM or Dex integration | authentication |
| ArgoCD | GitOps Controller |
| Cost Analyzer | Per-Namespace and Cluster Cost Analysis |
| Prometheus Push Gateway | Push-based metrics |
| Prometheus APM Exporter | Springboot Prometheus Exporter |
| Vault Operator | Hashicorp Vault Integration |
| Zipkin | Distributed Tracing |
This list does not include any stateful sets deployments (like elasticsearch or postgress), policy engines, additional metrics exporters, or even your workloads. Keep in mind that each needs to be configured and deployed to work in concert with your infrastructure and often one another as well. This will also affect sizing of your cluster nodes accordingly.
Takeaway: View your kubernetes clusters as a server. A server needs software to do anything useful, so will your cluster.
Conclusion
If you are using Kubernetes already then good for you! Welcome to the new declarative world we live in (#declarativenation). No matter how you consume your kubernetes, managed or bare metal, on your laptop or in the cloud, there is lots to consider. Generally, choosing managed Kubernetes clusters will be easier for most organizations. I’d just set your expectations to reasonable levels and things should be fine.
